关于生成引擎优化最佳实践的大多数建议都是从同一个地方开始的:找到人们使用人工智能工具的提示,跟踪哪些提示可以为您的品牌带来知名度,并围绕最高量的查询构建内容。
问题?该数据很大程度上是估计的。
生成式引擎优化(GEO)仍然很新,以至于准确测量它的基础设施还不存在。想想 GEO 与 SEO 有何不同:您所期望的 Semrush 或 Ahrefs 等工具所提供的成熟、可靠的信号需要数年时间才能开发出来。 GEO 测量尚未实现。平台所谓的“即时成交量”是经过建模和估计的,而且往往方向错误。
这篇文章详细分析了为什么即时成交量对于 GEO 策略来说是不可靠的基础,以及表现最好的团队会做什么。
要点
“提示量”是一个模型估计,而不是实际的用户数据,这使得它成为 GEO 决策的不可靠起点。
AI行为不一致;人们给出不同的措辞提示,模型返回不同的答案,使得小规模的模式难以信任。
AI“排名”不稳定;研究表明结果不断变化,因此跟踪 SEO 的方式无法转化为跟踪位置。
大多数数据源,无论是面板还是 API,都是有偏见的,或者不能反映人工智能工具中的真实用户行为。
引用漂移很高,这意味着即使对于相同的提示,来源和可见度也会逐月变化。
GEO 工具仍处于早期阶段,具有方向性,并非确定性的;相应地对待他们。
围绕 ICP 的实际语言进行聚类提示优于追逐供应商策划的查询列表。
一致的监控计划比痴迷于任何单个数据点更重要。
为什么提示交易量会误导您的 GEO 策略
1. 法学硕士没有搜索量:它是估计的,而不是测量的
最根本的问题是,谷歌公开搜索查询数据的方式并不存在真正的“人工智能搜索量”。法学硕士不会发布查询频率或搜索量等值。由于概率解码和提示上下文,即使对于相同的查询,他们的反应也会有所不同,有时是微妙的,有时是巨大的。它们还依赖于隐藏的上下文功能,例如用户历史记录、会话状态和对外部观察者不透明的嵌入。平台销售的“即时成交量”是模型估算,而不是直接测量。
2. LLM 的回答本质上是非确定性的
传统的关键字量之所以有效,是因为数百万人在谷歌中输入相同的短语,并且这些查询被记录下来。人工智能交互有着根本的不同。传统 SEO 中的搜索行为是重复的,数以百万计的相同短语驱动着稳定的流量指标。 LLM 的互动是对话式的、多变的。人们通常会在一次会话中以不同的方式重新表述问题,这使得小数据集的模式识别变得更加困难。
这种不确定性已经融入到法学硕士的工作方式中。他们使用概率方法生成文本,根据单词的可能性而不是遵循设定的模式来选择单词。相同的提示可能会产生不同的反应,这使得很难得出一致且准确的结论。
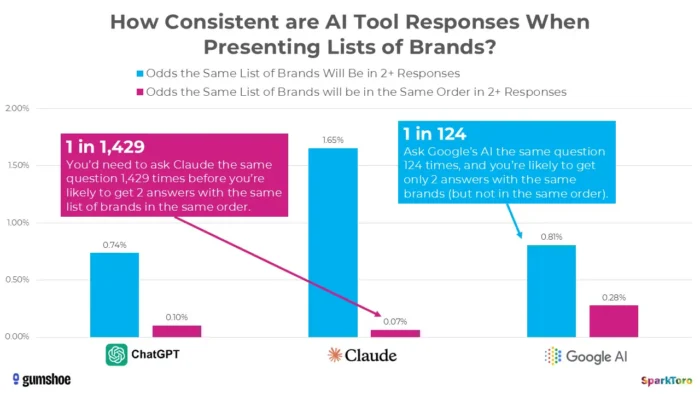
3. SparkToro 的研究表明排名本质上是随机的
最令人信服的证据来自 Rand Fishkin 和 Gumshoe.ai 于 2026 年 1 月进行的一项具有里程碑意义的研究。他们在 ChatGPT、Claude 和 Google AI 上测试了 600 名志愿者的 2,961 个提示。研究结果:在任意两个响应中获得相同品牌列表的几率不到百分之一,以相同顺序获得相同列表的几率不到千分之一。正如菲什金直言不讳的结论,任何给出“人工智能排名”的工具本质上都是编造的。
来源
SparkToro 的研究强调,即使使用相同的提示,人工智能生成的品牌推荐也会存在显着差异,这表明人工智能可见性的时间点测量可能反映的是波动性,而不是持久的绩效信号。
4. 基于小组的方法存在固有的偏差问题
像 Profound 这样的平台依靠选择加入的消费者小组来获取即时数据。 Profound 许可来自真实答案引擎用户的多个双重选择加入消费者小组的对话,每月有数亿条提示,并应用先进的概率模型来推断更广泛的频率、意图和情绪人口。
来源
虽然这听起来很可靠,但这些小组的选择加入性质意味着样本可能会偏向于更精通技术、更积极参与的用户,而不是一般人群实际如何提示人工智能工具的代表性横截面。
5. API 查询不能反映真实的人类行为
许多工具通过 API 查询 AI 模型来模拟用户提示,但这又带来了另一个差距。大多数人工智能跟踪工具依赖于 API 调用,而不是模仿人机界面的使用,早期研究表明 API 结果可能与界面结果不同,尽管这些差异的程度和影响需要进一步调查。查询数据以 API 为中心的本质也意味着结果与人类实际搜索的内容不一致。
6. 引文漂移巨大且不可预测
即使你忽略以上所有内容,人工智能引用的月度稳定性也低得惊人。 Profound 的一项研究逐月测量了引文漂移,并观察到即使对于相同的提示,被引领域也存在很大的变化。 Google AI Overviews 和 ChatGPT 显示每月有数十个百分点的变化。
来源
这意味着今天任何给定提示所附加的“数量”可能在下个月看起来完全不同,使其成为内容投资决策的不可靠基础。
7. 我们正处于 Semrush 之前的时代:工具尚不具备基础设施
对于法学硕士来说,我们仍处于 Semrush/Moz/Ahrefs 之前的时代。如今,没有人能够完全了解法学硕士对其业务的影响。警惕任何承诺完全可见性的供应商或顾问,因为这根本不可能。当前的跟踪数据应被视为有方向性且对决策有用,但不是决定性的。
生成引擎优化最佳实践:该怎么做
提示成交量是众多信号之一,但目前它是较弱的信号之一。以下是实际有效的生成引擎优化最佳实践。
从您的 ICP 开始,而不是仪表板
不要让估计的提示量决定您的 GEO 内容优先级,而是从您对受众的实际了解开始。您拥有的最强信号是您的理想客户档案。您最好的客户雇用您来解决哪些问题?他们用什么语言来描述这些问题?这些痛点,而不是供应商建模的即时估计,应该成为您在人工智能答案中优化的基础。
资料来源:营销人员
如果您已经完成了扎实的 ICP 工作,那么您已经获得了比任何提示量工具都能提供的更好的数据。
去你的观众已经谈论过的地方
通过深入受众公开、诚实地发言的地方,进行真正的受众研究。 Reddit 主题、利基论坛、LinkedIn 评论、Slack 社区以及 G2 和 Trustpilot 等评论网站是人们用自己的语言提出未经过滤的问题的地方。这正是一种自然语言,与人们如何提示人工智能工具密切相关。如果您的 ICP 在 Reddit 子版块中反复询问“我如何向 CFO 证明 X 的投资回报率”,那么这是一个比附在供应商策划的查询上的提示卷号更可靠的内容简介。
挖掘您自己的客户对话
面向客户的团队是 GEO 情报最未被充分利用的来源之一。销售电话录音、支持票、客户访谈和入职对话中都包含了真实买家在陷入困境、持怀疑态度或评估选项时所使用的准确措辞。该语言属于您的内容,并最终属于人工智能答案。如果你的销售团队每周都会听到同样的反对意见,那么很有可能有人向人工智能提出同样的问题。
围绕受众的语言聚集和组织提示
一旦您从 ICP 工作、论坛和客户对话中获得原始输入,下一步就是构建它。不要将每个潜在的提示视为一个孤立的目标,而是按意图和主题对它们进行分组。
围绕相似的主题或痛点进行快速聚类可以帮助您了解受众思考问题的模式,而不仅仅是他们如何表达单个问题。围绕“如何衡量 GEO 成功”的集群可能包括有关指标、报告、利益相关者沟通和基准测试的提示。每一个都值得内容,它们之间的重叠告诉你你的核心叙述应该是什么。
这是一个有意义的转变关键词研究逻辑。当您考虑 GEO 与 AEO 时,组织原则保持不变:围绕受众试图解决的问题的主题权威。按意图和主题进行及时组织可以让您系统地建立权威。
使用提示音量工具来完成他们真正擅长的事情
这并不意味着完全放弃 Profound 或 Writesonic 等平台。如果使用得当,它们对于方向意识确实很有用:发现主题差距,监控您的品牌是否出现在正确的对话中,以及随着时间的推移跟踪竞争对手的声音份额。
来源
错误在于使用它们作为关键字量的替代品,并让他们的估计驱动您创建的内容。让您的 ICP、受众研究和真实的客户对话告诉您要优化什么。然后使用即时成交量数据进行压力测试和监控,而不是做出决定。
制定切实可行的监控计划
考虑到人工智能输出中存在多少引文漂移,监控需要结构化且一致,而不是被动的。每季度检查一次品牌的人工智能知名度是不够的。核心提示集群的每月监控计划为您提供了合理的基线,用于发现有意义的变化,而不会过度索引噪音。
以下是实际处理方法。设置包含 20 到 30 个提示的定义列表,反映 ICP 最常见的问题。按照设定的节奏(至少每月一次)在受众最常使用的平台上运行它们,例如 ChatGPT、Perplexity 和 Google AI Overviews。跟踪您的品牌、内容或竞争对手是否出现。注意变化,但考虑到存在多少变化,不要对单月波动反应过度。您关注的是三到六个月的方向趋势,而不是每周的头寸。
这就是拥有真正的人工智能搜索优化策略的团队与对仪表板警报做出反应的团队的区别。监控通知;它不能决定。
底线
提示量尝试近似您可能已经可以直接访问的需求。在人工智能搜索中获胜的品牌并不是那些追逐最多追踪提示的品牌。他们足够深入地了解受众,能够在客户实际寻找的答案中找到答案。
