Більшість порад щодо найкращих методів генеративної оптимізації двигуна починаються з одного й того самого місця: знайдіть підказки, якими люди користуються за допомогою інструментів штучного інтелекту, відстежуйте, які з них забезпечують помітність вашого бренду, і створюйте контент навколо найбільших запитів.
проблема? Ці дані значною мірою оцінені.
Генеративна оптимізація механізму (GEO) все ще досить нова, тому інфраструктура для її точного вимірювання ще не існує. Подумайте, чим GEO відрізняється від SEO: зрілі, надійні сигнали, яких ви звикли очікувати від таких інструментів, як Semrush або Ahrefs, розробляли роки. Вимірювання GEO ще немає. Те, що платформи називають «швидким обсягом», є змодельованим, оціненим і часто неправильним.
У цьому дописі пояснюється, чому оперативний обсяг є ненадійною основою для вашої стратегії GEO, і що натомість роблять найефективніші команди.
Ключові висновки
«Швидкий обсяг» — це змодельована оцінка, а не фактичні дані користувача, що робить його ненадійною відправною точкою для прийняття GEO рішень.
Поведінка ШІ суперечлива; люди висловлюють підказки по-різному, а моделі повертають різні відповіді, що ускладнює довіру шаблонам у малому масштабі.
ШІ «рейтинги» нестабільні; Дослідження показують, що результати постійно змінюються, тому відстеження позиції так само, як ви відстежуєте SEO, не має значення.
Більшість джерел даних, будь то панелі чи API, упереджені або не відображають реальну поведінку користувачів у інструментах ШІ.
Зміщення цитувань є високим, тобто джерела та видимість змінюються з місяця в місяць навіть для однакових підказок.
Інструменти GEO все ще ранні та спрямовані, а не остаточні; поводитися з ними відповідно.
Кластеризація підказок навколо фактичної мови вашого ICP перевершує гонитву за списками запитів, які курує постачальник.
Послідовний графік моніторингу має більше значення, ніж захоплення будь-якою точкою даних.
Чому оперативний обсяг вводить в оману вашу стратегію GEO
1. LLMs не мають обсягу пошуку: він оцінюється, а не вимірюється
Найфундаментальніша проблема полягає в тому, що не існує справжнього «обсягу пошуку штучного інтелекту», яким Google надає дані пошукових запитів. LLM не публікують еквіваленти частоти запитів або обсягу пошуку. Їхні відповіді різняться, іноді незначно, а іноді різко, навіть на ідентичні запити через імовірнісне декодування та швидкий контекст. Вони також залежать від прихованих контекстних функцій, таких як історія користувача, стан сеансу та вбудовування, які не прозорі для зовнішніх спостерігачів. Що платформи продають як «миттєвий обсяг», це змодельована оцінка, а не пряме вимірювання.
2. Відповіді LLM є недетермінованими за своєю природою
Традиційний обсяг ключових слів працює, оскільки мільйони людей вводять ту саму фразу в Google, і ці запити реєструються. Взаємодії ШІ принципово відрізняються. Поведінка пошуку в традиційному SEO є повторюваною, з мільйонами однакових фраз, що забезпечують стабільні показники обсягу. LLM взаємодії є розмовними та змінними. Люди перефразують запитання по-різному, часто протягом одного сеансу, що ускладнює розпізнавання образів із невеликими наборами даних.
Цей недетермінізм закладений у роботу LLM. Вони створюють текст за допомогою імовірнісних методів, вибираючи слова на основі їхньої ймовірності, а не за встановленим шаблоном. Одна і та сама підказка може викликати різні відповіді, що ускладнює послідовні та точні висновки.
3. Дослідження SparkToro показують, що рейтинги по суті є випадковими
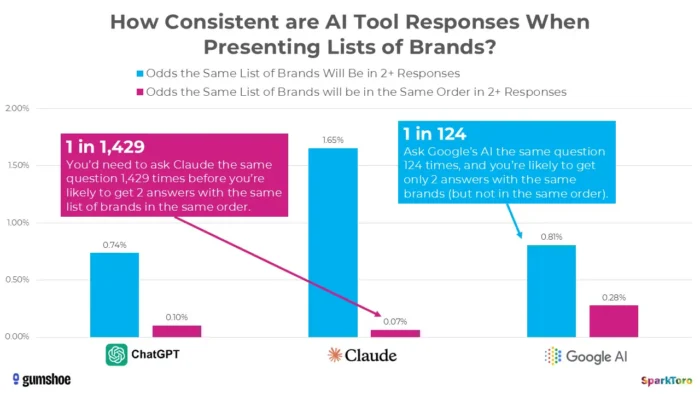
Найбільш переконливі докази походять із знакового дослідження, проведеного в січні 2026 року Рендом Фішкіним і Gumshoe.ai. Вони перевірили 2961 підказку на 600 добровольцях у ChatGPT, Claude і Google AI. Висновок: шанс отримати той самий список брендів у будь-яких двох відповідях менше ніж один із 100, і ймовірність того самого списку в тому самому порядку менше одного із 1000. Як прямо зробив висновок Фішкін, будь-який інструмент, який дає «рейтингову позицію в ШІ», по суті, вигадує його.
Джерело
Дослідження SparkToro підкреслює значну варіативність рекомендацій брендів, створених штучним інтелектом, навіть якщо використовуються ідентичні підказки, припускаючи, що вимірювання видимості штучного інтелекту в певний момент часу можуть відображати мінливість, а не тривалі сигнали продуктивності.
4. Методологія на основі панелей має властиві проблеми упередженості
Такі платформи, як Profound, покладаються на споживчі панелі, які підключаються для отримання оперативних даних. Profound ліцензує бесіди з кількома панелями споживачів із подвійною підтримкою реальних користувачів системи відповідей із масштабом сотень мільйонів запитів на місяць і застосовує розширене ймовірнісне моделювання для екстраполяції частоти, намірів і настроїв у ширших колах.населення.
Джерело
Хоча це звучить надійно, природа цих панелей за бажанням означає, що вибірка може бути спрямована в бік більш технічно підкованих, зацікавлених користувачів, а не репрезентативного перерізу того, як загальне населення насправді підказує інструменти ШІ.
5. Запити API не відображають справжню людську поведінку
Багато інструментів запитують моделі штучного інтелекту через API, щоб імітувати підказки користувача, але це створює ще одну прогалину. Більшість інструментів відстеження штучного інтелекту покладаються на виклики API, а не імітують використання інтерфейсу людини, і перші дослідження показують, що результати API можуть відрізнятися від результатів інтерфейсу, хоча величина та наслідки цих відмінностей потребують подальшого дослідження. Природа запиту даних, орієнтована на API, також означає, що результати не узгоджуються з тим, що насправді шукають люди.
6. Дрейф цитування є масовим і непередбачуваним
Навіть якщо ігнорувати все вищезазначене, місячна стабільність цитувань ШІ вражаюче низька. Дослідження, проведене Profound, виміряло зміну цитат за місяць і спостерігало дуже великі зміни в цитованих доменах навіть для ідентичних підказок. Google AI Overviews і ChatGPT показали місячні коливання на десятки процентних пунктів.
Джерело
Це означає, що «обсяг», доданий до будь-якого запиту сьогодні, може виглядати зовсім інакше наступного місяця, що робить його ненадійною основою для рішень про інвестиції в контент.
7. Ми живемо в епоху до Semrush: інструменти ще не мають інфраструктури
Ми все ще перебуваємо в епоху до Semrush/Moz/Ahrefs для LLM. Сьогодні ніхто не має повного бачення впливу LLM на їхній бізнес. Будьте обережні з будь-яким постачальником або консультантом, який обіцяє повну видимість, оскільки це просто поки що неможливо. Поточні дані відстеження слід розглядати як спрямовані та корисні для прийняття рішень, але не як остаточні.
Найкращі методи оптимізації генеративної системи: що робити натомість
Швидка гучність — це один із багатьох сигналів, і зараз він один із слабших. Ось найкращі методи генеративної оптимізації двигуна, які справді витримують.
Почніть зі свого ICP, а не з інформаційної панелі
Замість того, щоб дозволяти прогнозованому оперативному об’єму визначати ваші пріоритети GEO-контенту, почніть із того, що ви насправді знаєте про свою аудиторію. Найсильнішим сигналом для вас є ваш профіль ідеального клієнта. Для вирішення яких проблем вас наймають ваші найкращі клієнти? Якою мовою вони описують ці проблеми? Ці больові моменти, а не змодельовані швидкі оцінки постачальника, повинні бути основою того, для чого ви оптимізуєте відповіді ШІ.
Джерело: The Smarketers
Якщо ви виконали серйозну роботу з ВЧД, ви вже маєте кращі дані, ніж будь-який інструмент оперативного об’єму, який може надати вам.
Ідіть туди, де ваша аудиторія вже говорить
Скористайтеся дослідженнями реальної аудиторії, відвідавши аудиторію, яка говорить відкрито й чесно. Теми Reddit, спеціалізовані форуми, коментарі LinkedIn, спільноти Slack і сайти оглядів, такі як G2 і Trustpilot, — це місця, де люди ставлять невідфільтровані запитання своїми словами. Це саме той тип природної мови, який точно відповідає тому, як хтось підкаже інструмент ШІ. Якщо ваш ICP неодноразово запитує «як мені обґрунтувати рентабельність інвестицій X для мого фінансового директора» в subreddit, це набагато надійніший контент-бриф, ніж швидкий номер тому, доданий до запиту, куратором якого є постачальник.
Відстежуйте власні розмови з клієнтами
Команди, які працюють із клієнтами, є одним із найбільш маловикористовуваних джерел інформації про GEO. Записи розмов про продажі, квитки в службу підтримки, співбесіди з клієнтами та вступні бесіди багаті точними фразами, які використовують справжні покупці, коли вони застрягли, скептично налаштовані або оцінюють варіанти. Ця мова належить до вашого вмісту та, зрештою, до відповідей ШІ. Якщо ваша команда продажів щотижня чує одне й те саме заперечення, є велика ймовірність, що хтось задає штучному інтелекту те саме запитання.
Згрупуйте та організуйте підказки навколо мови вашої аудиторії
Після того, як ви отримаєте необроблені дані з роботи ICP, форумів і розмов із клієнтами, наступним кроком стане його структурування. Замість того, щоб розглядати кожну потенційну підказку як ізольовану ціль, згрупуйте їх за наміром і темою.
Швидке об’єднання навколо подібних тем або проблемних точок допомагає вам побачити закономірності у тому, як ваша аудиторія думає про проблему, а не лише те, як вони формулюють одне запитання. Кластер навколо «як виміряти успіх GEO» може включати підказки щодо показників, звітності, спілкування із зацікавленими сторонами та порівняльного аналізу. Кожне з них заслуговує на вміст, і накладення між ними підкаже вам, якою має бути ваша основна розповідь.
Це значущий перехід відлогіка дослідження ключових слів. Коли ви думаєте про GEO проти AEO, принцип організації залишається незмінним: тематичний авторитет навколо проблем, які ваша аудиторія намагається вирішити. Швидка організація за наміром і темою — це те, що дозволяє вам систематично формувати цей авторитет.
Використовуйте інструменти швидкої гучності для того, у чому вони справді гарні
Усе це не означає повну відмову від таких платформ, як Profound або Writesonic. За правильного використання вони справді корисні для орієнтації: виявлення прогалин у темах, відстеження того, чи з’являється ваш бренд у потрібних бесідах, і відстеження частки голосу порівняно з конкурентами з часом.
Джерело
Помилка полягає в тому, що ви використовуєте їх як замінник обсягу ключових слів і дозволяєте їхнім оцінкам керувати тим, що ви створюєте. Нехай ваш ICP, дослідження аудиторії та розмови з реальними клієнтами підкажуть вам, для чого оптимізувати. Потім використовуйте швидкі дані об’єму для перевірки тиску та моніторингу, а не для прийняття рішення.
Створіть графік моніторингу, який дійсно працює
Враховуючи те, наскільки великий дрейф цитувань існує в результатах ШІ, моніторинг має бути структурованим і послідовним, а не реагувати. Перевіряти видимість ШІ вашого бренду раз на квартал недостатньо. Щомісячний графік моніторингу для ваших основних кластерів підказок дає вам прийнятну базову лінію для виявлення значущих змін без надмірного індексування шуму.
Ось як підійти до цього практично. Налаштуйте визначений список із 20 до 30 підказок, які відображають найпоширеніші запитання вашого ICP. Запускайте їх із заданою частотою, принаймні щомісяця, на платформах, які найчастіше використовує ваша аудиторія, наприклад ChatGPT, Perplexity та Google AI Overviews. Відстежуйте, чи з’являється ваш бренд, ваш вміст або ваші конкуренти. Зверніть увагу на зміни, але не надто реагуйте на коливання за один місяць, зважаючи на те, скільки варіацій існує. Ви спостерігаєте за спрямованими тенденціями протягом трьох-шести місяців, а не за тижневими позиціями.
Це те, що відрізняє команди зі справжньою стратегією оптимізації пошуку AI від тих, хто реагує на сповіщення на інформаційній панелі. Моніторинг інформує; це не вирішує.
Підсумок
Підказка гучності намагається приблизно відповідати попиту, до якого ви вже можете мати прямий доступ. Бренди, які перемагають у пошуках зі штучним інтелектом, — це не ті, які женуться за підказками, які найчастіше відстежуються. Саме вони розуміють свою аудиторію достатньо глибоко, щоб знайти відповіді, які насправді шукають їхні клієнти.
