Enamik nõuandeid generatiivse mootori optimeerimise parimate tavade kohta algavad samast kohast: otsige üles, milliseid viipasid inimesed AI-tööriistadega kasutavad, jälgige, millised annavad teie brändile nähtavuse, ja looge sisu suurima mahuga päringute põhjal.
Probleem? Need andmed on suures osas hinnangulised.
Generatiivne mootori optimeerimine (GEO) on veel piisavalt uus, et selle täpseks mõõtmiseks vajalik infrastruktuur veel puudub. Mõelge, mille poolest GEO erineb SEO-st: küpsed ja usaldusväärsed signaalid, mida olete harjunud ootama sellistelt tööriistadelt nagu Semrush või Ahrefs, võttis aastaid aega. GEO mõõtmine pole veel olemas. See, mida platvormid nimetavad kiireks helitugevuseks, on modelleeritud, hinnatud ja sageli vale.
See postitus selgitab, miks kiire helitugevus on teie GEO strateegia jaoks ebausaldusväärne alus ja mida teevad selle asemel kõige paremini toimivad meeskonnad.
Võtmed kaasavõtmiseks
"Kiire maht" on modelleeritud hinnang, mitte tegelikud kasutajaandmed, mistõttu on see GEO otsuste lähtepunkt ebausaldusväärne.
AI käitumine on ebajärjekindel; inimesed sõnastavad viipasid erinevalt ja mudelid annavad erinevaid vastuseid, mistõttu on mustreid väikeses mahus raske usaldada.
AI "edetabel" on ebastabiilne; uuringud näitavad, et tulemused muutuvad pidevalt, nii et positsiooni jälgimine nii, nagu te SEO jälgite, ei tõlgi.
Enamik andmeallikaid, olgu need paneelid või API-d, on kallutatud või ei kajasta tegelikku kasutaja käitumist tehisintellekti tööriistades.
Tsiteeringute triiv on suur, mis tähendab, et allikad ja nähtavus muutuvad kuust kuusse isegi identsete viipade korral.
GEO tööriistad on veel varajased ja suunavad, mitte lõplikud; kohtle neid vastavalt.
ICP tegeliku keele rühmitusviipade toimivus ületab tarnija kureeritud päringuloendite otsimist.
Järjepidev seiregraafik on olulisem kui ühe andmepunkti kinnisidee.
Miks kiire helitugevus teie GEO strateegiat eksitab?
1. LLM-idel puudub otsingumaht: see on hinnanguline, mitte mõõdetud
Kõige põhilisem probleem on see, et pole tõelist tehisintellekti otsingumahtu, nagu Google avaldab otsingupäringu andmed. LLM-id ei avalda päringute sagedust ega otsingumahu ekvivalente. Nende vastused varieeruvad, mõnikord delikaatselt ja mõnikord dramaatiliselt, isegi identsete päringute puhul tõenäosusliku dekodeerimise ja kiire konteksti tõttu. Need sõltuvad ka peidetud kontekstuaalsetest funktsioonidest, nagu kasutaja ajalugu, seansi olek ja manustused, mis on välistele vaatlejatele läbipaistmatud. See, mida platvormid müüvad kiire mahuna, on modelleeritud hinnang, mitte otsene mõõtmine.
2. LLM-i vastused on oma olemuselt mittedeterministlikud
Traditsiooniline märksõnamaht töötab, sest miljonid inimesed sisestavad Google'isse sama fraasi ja need päringud logitakse. AI interaktsioonid on põhimõtteliselt erinevad. Otsingukäitumine traditsioonilises SEO-s on korduv ning miljonid identsed fraasid juhivad stabiilseid mahumõõdikuid. LLM-i suhtlus on vestluspõhine ja muutuv. Inimesed sõnastavad küsimusi erinevalt, sageli ühe seansi jooksul, muutes mustrite tuvastamise väikeste andmekogumitega raskemaks.
See mittedeterminism on seotud LLM-ide tööga. Nad toodavad teksti tõenäosuslike meetoditega, valides sõnu nende tõenäosuse järgi, mitte järgides kindlat mustrit. Sama viip võib anda erinevaid vastuseid, mis muudab järjepidevate ja täpsete järelduste tegemise keeruliseks.
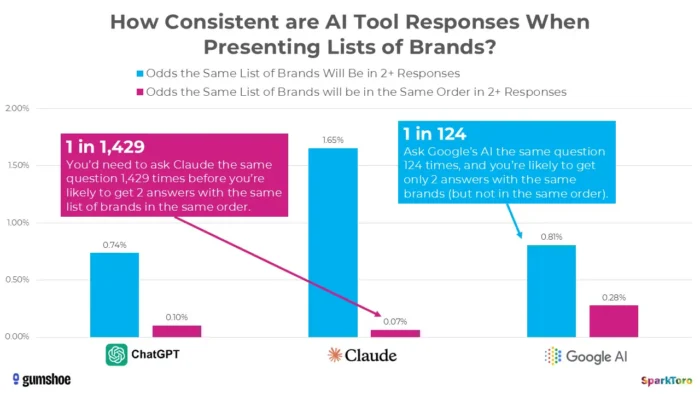
3. SparkToro uuringud näitavad, et pingeread on sisuliselt juhuslikud
Kõige veenvamad tõendid pärinevad Rand Fishkini ja Gumshoe.ai 2026. aasta jaanuaris läbiviidud märgilises uuringus. Nad testisid ChatGPT, Claude'i ja Google AI 600 vabatahtliku seas 2961 viipa. Järeldus: võimalus saada sama kaubamärgiloend kahe vastuse korral on väiksem kui üks 100-st ja sama loendi saamiseks samas järjekorras vähem kui üks 1000-st. Nagu Fishkin otsejoones järeldas, moodustab iga tööriist, mis annab tehisintellektis pingerea, selle sisuliselt välja.
Allikas
SparkToro uuringud tõstavad esile märkimisväärset varieeruvust tehisintellekti loodud brändisoovitustes isegi siis, kui kasutatakse identseid viipasid, mis viitab sellele, et AI-nähtavuse mõõtmised võivad peegeldada pigem volatiilsust kui püsivaid jõudlussignaale.
4. Paneelipõhisel metoodikal on loomupärased eelarvamusprobleemid
Platvormid, nagu Profound, toetuvad kiirete andmete hankimiseks tarbijapaneelidele. Põhjalikud litsentsid litsentsivad vestlusi mitmelt, kahekordselt valitud tarbijapaneelilt, mis koosnevad tõelistest vastusmootoritest kasutajate paneelidel, mille skaala ulatub sadadesse miljonitesse viipadesse kuus, ning rakendab täiustatud tõenäosusmudelit, et ekstrapoleerida sagedust, kavatsusi ja meeleolusid laiemalt.populatsioonid.
Allikas
Kuigi see kõlab jõuliselt, tähendab nende paneelide vabatahtlik olemus, et valim võib kalduda rohkem tehnoloogiliselt teadlikumate ja kaasatud kasutajate poole, mitte aga esinduslik läbilõige sellest, kuidas üldine elanikkond tegelikult tehisintellekti tööriistu nõuab.
5. API päringud ei peegelda tegelikku inimkäitumist
Paljud tööriistad küsivad kasutajaviipade simuleerimiseks AI-mudeleid API kaudu, kuid see toob kaasa veel ühe lünga. Enamik tehisintellekti jälgimistööriistu tugineb pigem API-kutstele, mitte inimliidese kasutust matkimisele, ja varased uuringud näitavad, et API tulemused võivad liidese tulemustest erineda, kuigi nende erinevuste ulatus ja tagajärjed nõuavad täiendavat uurimist. Andmete päringute API-keskne olemus tähendab ka seda, et tulemused ei ole vastavuses sellega, mida inimesed tegelikult otsivad.
6. Tsiteerimise triiv on tohutu ja ettearvamatu
Isegi kui te ignoreerite kõike ülaltoodud, on AI tsitaatide igakuine stabiilsus šokeerivalt madal. Profoundi uuring mõõtis tsitaatide triivi kuude lõikes ja täheldas viidatud domeenides väga suuri muutusi isegi identsete viipade korral. Google'i tehisintellekti ülevaated ja ChatGPT näitasid kümnete protsendipunktide ulatuses igakuiseid variatsioone.
Allikas
See tähendab, et täna mis tahes viipale lisatud "maht" võib järgmisel kuul välja näha täiesti erinev, muutes selle sisu investeerimisotsuste tegemiseks ebausaldusväärseks.
7. Oleme Semrushi-eelses ajastus: tööriistadel pole veel infrastruktuuri
LLM-ide jaoks oleme endiselt Semrushi/Moz/Ahrefsi-eelses ajastus. Kellelgi pole täna täielikku ülevaadet LLM-i mõjust nende ettevõttele. Olge ettevaatlik, kui müüja või konsultant lubab täielikku nähtavust, sest see pole lihtsalt veel võimalik. Praeguseid jälgimisandmeid tuleks käsitleda suunavate ja otsuste tegemisel kasulike, kuid mitte lõplike andmetena.
Generatiivse mootori optimeerimise parimad tavad: mida selle asemel teha
Kiire helitugevus on üks signaal paljudest ja praegu on see üks nõrgemaid. Siin on generatiivse mootori optimeerimise parimad tavad, mis tegelikult kehtivad.
Alustage oma ICP-st, mitte armatuurlauast
Selle asemel, et lasta hinnangulisel kiirel helitugevusel dikteerida oma GEO sisu prioriteete, alustage sellest, mida te oma vaatajaskonna kohta tegelikult teate. Kõige tugevam signaal, mis teil on, on teie ideaalse kliendi profiil. Milliseid probleeme lahendavad teie parimad kliendid, kes teid palkavad? Millist keelt nad nende probleemide kirjeldamiseks kasutavad? Need valupunktid, mitte müüja modelleeritud kiired hinnangud, peaksid olema tehisintellekti vastuste optimeerimise aluseks.
Allikas: The Smarketers
Kui olete teinud tugevat ICP-tööd, on teil juba paremad andmed, kui ükski kiire helitugevuse tööriist teile pakkuda suudab.
Minge sinna, kus teie publik juba räägib
Osalege tõelises publiku-uuringus, minnes sinna, kus teie publik räägib avatult ja ausalt. Redditi lõimed, nišifoorumid, LinkedIni kommentaarid, Slacki kogukonnad ja arvustuste saidid, nagu G2 ja Trustpilot, on kohad, kus inimesed küsivad oma sõnadega filtreerimata küsimusi. See on täpselt selline loomulik keel, mis vastab täpselt sellele, kuidas keegi AI-tööriista küsib. Kui teie ICP küsib alamreditis korduvalt „kuidas põhjendada X ROI-d oma finantsjuhile”, on see palju usaldusväärsem sisukokkuvõte kui tarnija kureeritud päringule lisatud viip köitenumber.
Kaevandage oma klientide vestlusi
Kliendile suunatud meeskonnad on üks kõige vähem kasutatud GEO luureallikaid. Müügikõnede salvestised, tugipiletid, kliendiintervjuud ja sisseastumisvestlused on rikkad täpsete väljenditega, mida tõelised ostjad kasutavad, kui nad on ummikus, skeptilised või hindavad võimalusi. See keel kuulub teie sisu ja lõpuks AI vastuste hulka. Kui teie müügimeeskond kuuleb igal nädalal sama vastuväidet, on suur tõenäosus, et keegi esitab tehisintellektile sama küsimuse.
Klasterdage ja korraldage viipasid oma vaatajaskonna keele järgi
Kui olete oma ICP-tööst, foorumitest ja klientide vestlustest toores sisendi saanud, on järgmine samm selle struktureerimine. Selle asemel, et käsitleda iga potentsiaalset viipa isoleeritud sihtmärgina, rühmitage need kavatsuse ja teema järgi.
Kiire rühmitamine sarnaste teemade või valupunktide ümber aitab teil näha mustreid selles, kuidas teie publik probleemist mõtleb, mitte ainult seda, kuidas nad ühe küsimuse sõnastavad. GEO edukuse mõõtmise klaster võib sisaldada viipasid mõõdikute, aruandluse, sidusrühmadega suhtlemise ja võrdlusuuringute kohta. Igaüks neist väärib sisu ja nendevaheline kattuvus ütleb teile, milline peaks olema teie põhijutustus.
See on tähendusrikas nihemärksõna uurimise loogika. Kui mõtlete GEO-le versus AEO-le, jääb korralduspõhimõte samaks: aktuaalne autoriteet probleemide üle, mida teie publik püüab lahendada. Kiire organiseerimine kavatsuse ja teema järgi on see, mis võimaldab teil seda autoriteeti süstemaatiliselt luua.
Kasutage helitugevuse viipetööriistu selle jaoks, milles nad tegelikult head on
Ükski neist ei tähenda platvormide, nagu Profound või Writesonic, täielikku loobumist. Õige kasutamise korral on need tõeliselt kasulikud suunateadlikkuse suurendamiseks: teemalünkade tuvastamiseks, selle jälgimiseks, kas teie bränd ilmub õigetes vestlustes, ja aja jooksul konkurentide hääleosa jälgimiseks.
Allikas
Viga on selles, et kasutatakse neid märksõnade mahu asendajana ja lastakse nende prognoosidel juhtida seda, mida loote. Laske oma ICP-l, publikuuuringul ja tõelistel kliendivestlustel öelda, mille jaoks optimeerida. Seejärel kasutage kiireid mahuandmeid rõhu testimiseks ja jälgimiseks, mitte otsustamiseks.
Koostage seirekava, mis tegelikult töötab
Arvestades, kui palju tsitaatide triivi AI-väljundites esineb, peab jälgimine olema pigem struktureeritud ja järjepidev, mitte reageerima. Oma brändi tehisintellekti nähtavuse kontrollimisest kord kvartalis ei piisa. Peamiste viipade klastrite igakuine seiregraafik annab teile mõistliku lähtetaseme oluliste nihete tuvastamiseks ilma müra üleindekseerimiseta.
Siin on, kuidas sellele praktiliselt läheneda. Koostage määratletud loend 20–30 viipast, mis kajastavad teie ICP kõige levinumaid küsimusi. Käivitage neid vähemalt kord kuus kindlal sagedusel platvormidel, mida teie vaatajaskond kõige enam kasutab, näiteks ChatGPT, Perplexity ja Google AI ülevaated. Jälgige, kas teie bränd, sisu või konkurendid ilmuvad. Pange tähele muudatusi, kuid ärge reageerige üle ühekuulistele kõikumistele, arvestades, kui palju erinevusi on. See, mida te jälgite, on suunatrendid kolme kuni kuue kuu jooksul, mitte nädalast nädalasse.
See eristab tõelise tehisintellekti otsingu optimeerimise strateegiaga meeskondi nendest, kes reageerivad armatuurlaua hoiatustele. Järelevalve teavitab; see ei otsusta.
Alumine rida
Viipade helitugevus proovib ligikaudselt hinnata nõudlust, millele teil võib juba olla otsene juurdepääs. Tehisintellekti otsingus võitnud kaubamärgid ei jahi kõige enam jälgitavaid viipasid. Just nemad mõistavad oma publikut piisavalt sügavalt, et ilmuda vastustes, mida nende kliendid tegelikult otsivad.
