Die meisten Ratschläge zu Best Practices für die generative Engine-Optimierung beginnen an derselben Stelle: Finden Sie die Eingabeaufforderungen, die Menschen mit KI-Tools verwenden, verfolgen Sie, welche Ihrer Marke Sichtbarkeit verleihen, und erstellen Sie Inhalte rund um die Suchanfragen mit dem höchsten Volumen.
Das Problem? Bei diesen Daten handelt es sich größtenteils um Schätzungen.
Die generative Motoroptimierung (GEO) ist noch so neu, dass die Infrastruktur für eine genaue Messung noch nicht vorhanden ist. Denken Sie daran, wie sich GEO von SEO unterscheidet: Die Entwicklung der ausgereiften, zuverlässigen Signale, die Sie von Tools wie SEMrush oder Ahrefs erwarten, hat Jahre gedauert. Die GEO-Messung ist noch nicht so weit. Was Plattformen als „promptes Volumen“ bezeichnen, ist modelliert, geschätzt und weist häufig eine falsche Richtung auf.
In diesem Beitrag wird erläutert, warum schnelles Volumen eine unzuverlässige Grundlage für Ihre GEO-Strategie darstellt und was die leistungsstärksten Teams stattdessen tun.
Wichtige Erkenntnisse
Beim „prompten Volumen“ handelt es sich um eine modellierte Schätzung und nicht um tatsächliche Benutzerdaten, was es zu einem unzuverlässigen Ausgangspunkt für GEO-Entscheidungen macht.
Das KI-Verhalten ist inkonsistent; Menschen formulieren Eingabeaufforderungen unterschiedlich und Modelle geben unterschiedliche Antworten zurück, was es schwierig macht, Mustern im kleinen Maßstab zu vertrauen.
KI-„Rankings“ sind instabil; Studien zeigen, dass sich die Ergebnisse ständig ändern, daher lässt sich die Verfolgung der Position nicht auf die Art und Weise übertragen, wie Sie SEO verfolgen.
Die meisten Datenquellen, ob Panels oder APIs, sind voreingenommen oder spiegeln nicht das tatsächliche Benutzerverhalten in KI-Tools wider.
Die Zitierdrift ist hoch, was bedeutet, dass sich Quellen und Sichtbarkeit von Monat zu Monat ändern, selbst bei identischen Eingabeaufforderungen.
GEO-Tools sind noch früh und richtungsweisend, nicht endgültig; Behandle sie entsprechend.
Das Clustern von Eingabeaufforderungen rund um die tatsächliche Sprache Ihres ICP übertrifft die Verfolgung von vom Anbieter kuratierten Abfragelisten.
Ein konsistenter Überwachungsplan ist wichtiger als die Besessenheit über einen einzelnen Datenpunkt.
Warum schnelles Volumen Ihre GEO-Strategie in die Irre führt
1. LLMs haben kein Suchvolumen: Es wird geschätzt, nicht gemessen
Das grundlegendste Problem besteht darin, dass es kein echtes „KI-Suchvolumen“ in der Art und Weise gibt, wie Google Suchanfragendaten offenlegt. LLMs veröffentlichen keine Abfragehäufigkeit oder Suchvolumenäquivalente. Ihre Antworten variieren manchmal subtil und manchmal dramatisch, selbst bei identischen Anfragen, aufgrund der probabilistischen Dekodierung und des Eingabeaufforderungskontexts. Sie hängen auch von versteckten kontextbezogenen Funktionen wie Benutzerverlauf, Sitzungsstatus und Einbettungen ab, die für externe Beobachter undurchsichtig sind. Was Plattformen als „promptes Volumen“ verkaufen, ist eine modellierte Schätzung und keine direkte Messung.
2. LLM-Antworten sind von Natur aus nicht deterministisch
Das herkömmliche Keyword-Volumen funktioniert, weil Millionen von Menschen dieselbe Phrase in Google eingeben und diese Abfragen protokolliert werden. KI-Interaktionen sind grundlegend anders. Das Suchverhalten im traditionellen SEO ist repetitiv, wobei Millionen identischer Phrasen zu stabilen Volumenmetriken führen. LLM-Interaktionen sind konversationell und variabel. Menschen formulieren Fragen unterschiedlich um, oft innerhalb einer einzigen Sitzung, was die Mustererkennung bei kleinen Datensätzen schwieriger macht.
Dieser Nichtdeterminismus ist fest in die Funktionsweise von LLMs eingebettet. Sie erstellen Texte mit probabilistischen Methoden und wählen Wörter auf der Grundlage ihrer Wahrscheinlichkeit aus, anstatt einem festgelegten Muster zu folgen. Die gleiche Eingabeaufforderung kann unterschiedliche Antworten hervorrufen, was es schwierig macht, konsistente und genaue Schlussfolgerungen zu ziehen.
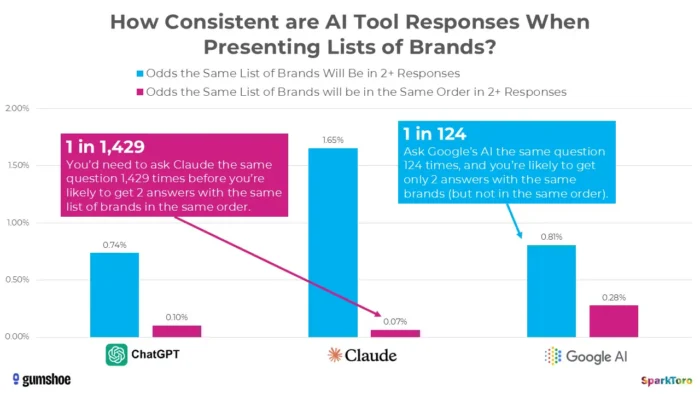
3. Die Untersuchungen von SparkToro zeigen, dass Rankings im Wesentlichen zufällig sind
Der überzeugendste Beweis stammt aus einer bahnbrechenden Studie von Rand Fishkin und Gumshoe.ai vom Januar 2026. Sie testeten 2.961 Eingabeaufforderungen von 600 Freiwilligen auf ChatGPT, Claude und Google AI. Das Ergebnis: Die Wahrscheinlichkeit, in zwei beliebigen Antworten dieselbe Markenliste zu erhalten, liegt bei weniger als eins zu 100, und die Wahrscheinlichkeit, dieselbe Liste in derselben Reihenfolge zu erhalten, liegt bei weniger als eins zu 1.000. Wie Fishkin unverblümt schlussfolgerte, ist jedes Tool, das eine „Rangliste in der KI“ angibt, im Grunde nur eine Verbesserung.
Quelle
Untersuchungen von SparkToro zeigen eine erhebliche Variabilität bei KI-generierten Markenempfehlungen, selbst wenn identische Eingabeaufforderungen verwendet werden, was darauf hindeutet, dass KI-Sichtbarkeitsmessungen zu einem bestimmten Zeitpunkt eher Volatilität als dauerhafte Leistungssignale widerspiegeln.
4. Die Panel-basierte Methodik weist inhärente Verzerrungsprobleme auf
Plattformen wie Profound verlassen sich auf Opt-in-Verbraucherpanels, um ihre Echtzeitdaten zu erhalten. Profound lizenziert Konversationen aus mehreren Double-Opt-in-Verbraucherpanels echter Antwortmaschinenbenutzer mit einer Größenordnung von Hunderten Millionen Eingabeaufforderungen pro Monat und wendet fortschrittliche probabilistische Modellierung an, um Häufigkeit, Absicht und Stimmung im weiteren Sinne zu extrapolierenPopulationen.
Quelle
Das hört sich zwar robust an, aber der Opt-in-Charakter dieser Panels bedeutet, dass sich die Stichprobe möglicherweise eher auf technisch versierte, engagierte Benutzer konzentriert und keinen repräsentativen Querschnitt dessen darstellt, wie die allgemeine Bevölkerung tatsächlich KI-Tools anregt.
5. API-Abfragen spiegeln nicht das echte menschliche Verhalten wider
Viele Tools fragen KI-Modelle über eine API ab, um Benutzereingaben zu simulieren. Dies führt jedoch zu einer weiteren Lücke. Die meisten KI-Tracking-Tools basieren auf API-Aufrufen und nicht auf der Nachahmung der Nutzung menschlicher Schnittstellen. Erste Forschungsergebnisse deuten darauf hin, dass API-Ergebnisse von Schnittstellenergebnissen abweichen können. Das Ausmaß und die Auswirkungen dieser Unterschiede erfordern jedoch weitere Untersuchungen. Der API-fokussierte Charakter der Datenabfrage bedeutet auch, dass die Ergebnisse nicht mit dem übereinstimmen, wonach Menschen tatsächlich suchen.
6. Der Zitatdrift ist massiv und unvorhersehbar
Selbst wenn Sie alles oben Genannte ignorieren, ist die monatliche Stabilität der KI-Zitate erschreckend niedrig. Eine Studie von Profound hat die Zitierdrift Monat für Monat gemessen und selbst bei identischen Eingabeaufforderungen sehr große Veränderungen in den zitierten Domänen beobachtet. Google AI Overviews und ChatGPT zeigten monatliche Schwankungen von Dutzenden Prozentpunkten.
Quelle
Das bedeutet, dass das „Volumen“, das heute mit einer bestimmten Eingabeaufforderung verbunden ist, im nächsten Monat völlig anders aussehen kann, was es zu einer unzuverlässigen Grundlage für Content-Investitionsentscheidungen macht.
7. Wir befinden uns in einer Zeit vor SEMrush: Den Tools fehlt noch die Infrastruktur
Wir befinden uns für LLMs immer noch in einer Zeit vor SEMrush/Moz/Ahrefs. Niemand hat heute einen vollständigen Einblick in die Auswirkungen von LLM auf sein Unternehmen. Seien Sie vorsichtig bei Anbietern oder Beratern, die vollständige Transparenz versprechen, denn das ist einfach noch nicht möglich. Aktuelle Trackingdaten sollten als richtungsweisend und entscheidungsnützlich betrachtet werden, jedoch nicht als endgültig.
Best Practices für die generative Motoroptimierung: Was stattdessen zu tun ist
Prompt-Lautstärke ist ein Signal unter vielen, und im Moment ist es eines der schwächeren. Hier sind die Best Practices für die generative Engine-Optimierung, die sich tatsächlich bewährt haben.
Beginnen Sie mit Ihrem ICP, nicht mit einem Dashboard
Anstatt sich die Prioritäten Ihrer GEO-Inhalte von der geschätzten Aufforderungsmenge diktieren zu lassen, beginnen Sie mit dem, was Sie tatsächlich über Ihr Publikum wissen. Das stärkste Signal, das Sie haben, ist Ihr ideales Kundenprofil. Für welche Probleme beauftragen Sie Ihre besten Kunden mit der Lösung? Mit welcher Sprache beschreiben sie diese Probleme? Diese Schwachstellen und nicht die modellierten Sofortschätzungen eines Anbieters sollten die Grundlage für die Optimierung Ihrer KI-Antworten sein.
Quelle: The Smarketers
Wenn Sie solide ICP-Arbeit geleistet haben, verfügen Sie bereits über bessere Daten, als Ihnen jedes Prompt-Volume-Tool liefern kann.
Gehen Sie dorthin, wo Ihr Publikum bereits spricht
Fügen Sie echte Publikumsforschung hinzu, indem Sie dorthin gehen, wo Ihr Publikum offen und ehrlich spricht. Reddit-Threads, Nischenforen, LinkedIn-Kommentare, Slack-Communitys und Bewertungsseiten wie G2 und Trustpilot sind Orte, an denen Menschen ungefilterte Fragen in ihren eigenen Worten stellen. Das ist genau die Art von natürlicher Sprache, die der Art und Weise, wie jemand ein KI-Tool ansteuern würde, sehr nahe kommt. Wenn Ihr ICP in einem Subreddit wiederholt fragt: „Wie rechtfertige ich den ROI von
Analysieren Sie Ihre eigenen Kundengespräche
Kundenorientierte Teams sind eine der am wenigsten genutzten Quellen für GEO-Informationen. Aufzeichnungen von Verkaufsgesprächen, Support-Tickets, Kundeninterviews und Onboarding-Gesprächen enthalten genau die Formulierungen, die echte Käufer verwenden, wenn sie nicht weiterkommen, skeptisch sind oder Optionen prüfen. Diese Sprache gehört in Ihre Inhalte und letztendlich in KI-Antworten. Wenn Ihr Vertriebsteam jede Woche denselben Einwand hört, besteht eine gute Chance, dass jemand einer KI dieselbe Frage stellt.
Gruppieren und organisieren Sie Ansagen entsprechend der Sprache Ihrer Zielgruppe
Sobald Sie rohen Input aus Ihrer ICP-Arbeit, Foren und Kundengesprächen haben, besteht der nächste Schritt darin, ihn zu strukturieren. Anstatt jede potenzielle Aufforderung als isoliertes Ziel zu behandeln, gruppieren Sie sie nach Absicht und Thema.
Durch die zeitnahe Gruppierung ähnlicher Themen oder Schwachstellen können Sie Muster darin erkennen, wie Ihr Publikum über ein Problem denkt und nicht nur, wie es eine einzelne Frage formuliert. Ein Cluster zum Thema „Wie misst man den GEO-Erfolg“ könnte Hinweise zu Kennzahlen, Berichten, Stakeholder-Kommunikation und Benchmarking enthalten. Jedes davon verdient Inhalt, und die Überschneidung zwischen ihnen zeigt Ihnen, wie Ihre Kernerzählung aussehen sollte.
Dies ist eine bedeutungsvolle Abkehr vonKeyword-Recherche-Logik. Wenn Sie über GEO versus AEO nachdenken, bleibt das Organisationsprinzip dasselbe: thematische Autorität rund um die Probleme, die Ihr Publikum zu lösen versucht. Durch eine schnelle Organisation nach Absicht und Thema können Sie diese Autorität systematisch aufbauen.
Nutzen Sie Prompt-Volume-Tools für das, worin sie wirklich gut sind
Nichts davon bedeutet, Plattformen wie Profound oder Writesonic vollständig aufzugeben. Bei richtiger Anwendung sind sie wirklich nützlich für die Richtungswahrnehmung: Sie erkennen Themenlücken, überwachen, ob Ihre Marke in den richtigen Gesprächen erscheint, und verfolgen den Share of Voice im Vergleich zu Mitbewerbern im Laufe der Zeit.
Quelle
Der Fehler besteht darin, sie als Ersatz für das Keyword-Volumen zu verwenden und ihre Schätzungen als Grundlage für Ihre Erstellung zu verwenden. Lassen Sie sich von Ihrem ICP, Ihrer Zielgruppenforschung und echten Kundengesprächen sagen, worauf Sie optimieren müssen. Nutzen Sie dann die sofortigen Volumendaten zur Druckprüfung und Überwachung, nicht zur Entscheidung.
Erstellen Sie einen Überwachungsplan, der tatsächlich funktioniert
Angesichts der starken Zitationsdrift bei KI-Ausgaben muss die Überwachung strukturiert und konsistent und nicht reaktiv sein. Es reicht nicht aus, die KI-Sichtbarkeit Ihrer Marke einmal im Quartal zu überprüfen. Ein monatlicher Überwachungsplan für Ihre Kern-Prompt-Cluster bietet Ihnen eine vernünftige Basis, um bedeutsame Veränderungen zu erkennen, ohne übermäßig auf Rauschen zu achten.
Hier erfahren Sie, wie Sie es praktisch angehen. Erstellen Sie eine definierte Liste mit 20 bis 30 Eingabeaufforderungen, die die häufigsten Fragen Ihres ICP widerspiegeln. Führen Sie sie in einem festgelegten Rhythmus, mindestens monatlich, auf den Plattformen aus, die Ihre Zielgruppe am häufigsten nutzt, wie ChatGPT, Perplexity und Google AI Overviews. Verfolgen Sie, ob Ihre Marke, Ihre Inhalte oder Ihre Konkurrenten erscheinen. Beachten Sie Änderungen, aber reagieren Sie angesichts der großen Schwankungen nicht zu stark auf Schwankungen innerhalb eines Monats. Sie achten auf Richtungstrends über drei bis sechs Monate und nicht auf wöchentliche Positionen.
Das ist es, was Teams mit einer echten KI-Suchoptimierungsstrategie von denen unterscheidet, die auf Dashboard-Warnungen reagieren. Überwachung informiert; es entscheidet nicht.
Das Fazit
Das Prompt-Volumen versucht, die Nachfrage abzuschätzen, auf die Sie möglicherweise bereits direkten Zugriff haben. Die Marken, die bei der KI-Suche gewinnen, sind nicht diejenigen, die den am häufigsten verfolgten Eingabeaufforderungen nachjagen. Sie sind diejenigen, die ihr Publikum so gut verstehen, dass sie in den Antworten auftauchen, nach denen ihre Kunden tatsächlich suchen.
