Većina savjeta o najboljim praksama generativne optimizacije motora počinje na istom mjestu: pronađite upite koje ljudi koriste s alatima umjetne inteligencije, pratite koji daju vidljivost vašem brendu i izgradite sadržaj oko upita s najvećim opsegom.
problem? Ti su podaci uglavnom procijenjeni.
Generativna optimizacija motora (GEO) još je uvijek dovoljno nova da infrastruktura za njezino precizno mjerenje još ne postoji. Razmislite o tome kako se GEO razlikuje od SEO-a: zreli, pouzdani signali koje ste očekivali od alata kao što su Semrush ili Ahrefs bile su potrebne godinama za razvoj. GEO mjerenje još ne postoji. Ono što platforme nazivaju "brzom količinom" modelirano je, procijenjeno i često pogrešno usmjereno.
Ovaj post razjašnjava zašto je brzi volumen nepouzdan temelj za vašu GEO strategiju i što umjesto toga rade najuspješniji timovi.
Ključni podaci za van
"Prompt volume" je modelirana procjena, a ne stvarni korisnički podaci, što ga čini nepouzdanom početnom točkom za GEO odluke.
Ponašanje AI je nedosljedno; fraza ljudi upućuje drugačije, a modeli vraćaju različite odgovore, zbog čega je teško vjerovati obrascima u maloj mjeri.
AI "rangiranje" je nestabilno; studije pokazuju da se rezultati stalno mijenjaju, tako da praćenje pozicije na način na koji pratite SEO ne vrijedi.
Većina izvora podataka, bilo panela ili API-ja, pristrani su ili ne odražavaju stvarno ponašanje korisnika u AI alatima.
Pomak citata je velik, što znači da se izvori i vidljivost mijenjaju iz mjeseca u mjesec čak i za identične upite.
GEO alati su još rani i usmjereni, a ne konačni; postupajte s njima u skladu s tim.
Grupiranje upita oko stvarnog jezika vašeg ICP-a nadmašuje jurenje popisa upita koje je kurirao dobavljač.
Dosljedan raspored praćenja važniji je od opsjednutosti bilo kojom pojedinačnom podatkovnom točkom.
Zašto Prompt Volume dovodi u zabludu vašu GEO strategiju
1. LLM nemaju opseg pretraživanja: procjenjuje se, a ne mjeri
Najosnovniji problem je taj što ne postoji pravi "AI opseg pretraživanja" način na koji Google izlaže podatke o upitima za pretraživanje. LLM ne objavljuju učestalost upita ili ekvivalente opsega pretraživanja. Njihovi odgovori variraju, ponekad suptilno, a ponekad dramatično, čak i za identične upite, zbog vjerojatnosnog dekodiranja i brzog konteksta. Također ovise o skrivenim kontekstualnim značajkama poput korisničke povijesti, stanja sesije i ugrađivanja koja su neprozirna vanjskim promatračima. Ono što platforme prodaju kao "prompt volume" je modelirana procjena, a ne izravno mjerenje.
2. LLM odgovori su po prirodi nedeterministički
Tradicionalna količina ključnih riječi funkcionira jer milijuni ljudi upisuju istu frazu u Google i ti se upiti bilježe. Interakcije umjetne inteligencije bitno su različite. Ponašanje pretraživanja u tradicionalnom SEO-u se ponavlja, s milijunima identičnih izraza koji pokreću stabilne metrike opsega. LLM interakcije su konverzacijske i promjenjive. Ljudi različito preformuliraju pitanja, često unutar jedne sesije, što otežava prepoznavanje uzoraka s malim skupovima podataka.
Ovaj ne-determinizam utkan je u rad LLM-a. Oni proizvode tekst korištenjem probabilističkih metoda, birajući riječi na temelju njihove vjerojatnosti, a ne slijedeći postavljeni obrazac. Isti upit može proizvesti različite odgovore, što otežava izvođenje dosljednih i točnih zaključaka.
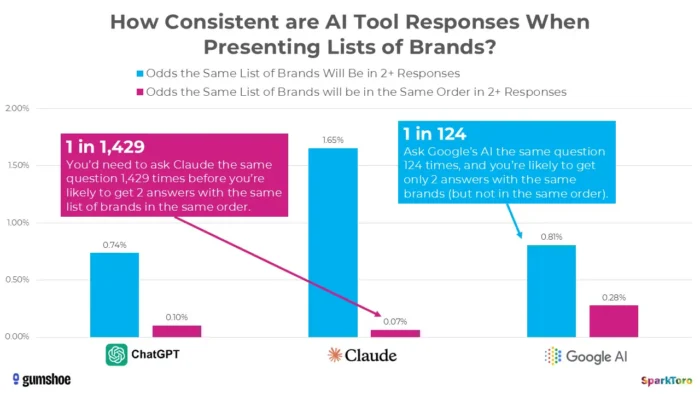
3. SparkToro istraživanje pokazuje da su rangiranja u biti nasumična
Najuvjerljiviji dokaz dolazi iz značajne studije Randa Fishkina i Gumshoe.aia iz siječnja 2026. Testirali su 2961 upit na 600 volontera na ChatGPT-u, Claudeu i Google AI-ju. Otkriće: postoji manje od jedan prema 100 šanse da dobijete isti popis robnih marki u bilo koja dva odgovora, a manje od jedan prema 1000 šanse da dobijete isti popis istim redoslijedom. Kao što je Fishkin otvoreno zaključio, bilo koji alat koji daje "rangiranje u umjetnoj inteligenciji" u biti ga izmišlja.
Izvor
Istraživanje koje je proveo SparkToro naglašava značajnu varijabilnost u preporukama za robne marke koje generira umjetna inteligencija čak i kada se koriste identični odgovori, sugerirajući da mjerenja vidljivosti umjetne inteligencije u određenom trenutku mogu odražavati volatilnost, a ne trajne signale performansi.
4. Metodologija temeljena na panelu ima inherentne probleme pristranosti
Platforme poput Profounda oslanjaju se na opt-in potrošačke panele za izvor svojih brzih podataka. Profound licencira razgovore s višestrukim potrošačkim panelima s dvostrukom opt-in stvarnim korisnicima mehanizma odgovora, s opsegom od stotina milijuna upita mjesečno i primjenjuje napredno modeliranje vjerojatnosti za ekstrapolaciju učestalosti, namjere i osjećaja u širem smislupopulacije.
Izvor
Iako ovo zvuči robusno, opt-in priroda ovih panela znači da uzorak može skrenuti prema više tehnički potkovanih, angažiranih korisnika, a ne prema reprezentativnom presjeku načina na koji opća populacija zapravo traži AI alate.
5. API upiti ne odražavaju stvarno ljudsko ponašanje
Mnogi alati postavljaju upite AI modelima putem API-ja za simulaciju korisničkih upita, ali to uvodi još jednu prazninu. Većina alata za praćenje pomoću umjetne inteligencije oslanja se na pozive API-ja, a ne na oponašanje upotrebe ljudskog sučelja, a rana istraživanja sugeriraju da se rezultati API-ja mogu razlikovati od rezultata sučelja, iako veličina i implikacije tih razlika zahtijevaju daljnje istraživanje. Priroda postavljanja upita za podatke usmjerena na API također znači da rezultati nisu usklađeni s onim što ljudi zapravo traže.
6. Citation Drift je ogroman i nepredvidiv
Čak i ako zanemarite sve gore navedeno, mjesečna stabilnost citata umjetne inteligencije je šokantno niska. Studija koju je proveo Profound mjerila je pomicanje citata iz mjeseca u mjesec i uočila vrlo velike promjene u citiranim domenama čak i za identične upite. Google AI Pregledi i ChatGPT pokazali su mjesečne varijacije od desetak postotnih bodova.
Izvor
To znači da bi "volumen" priložen bilo kojem današnjem upitu mogao izgledati potpuno drugačije sljedeći mjesec, što ga čini nepouzdanim temeljem za odluke o ulaganju u sadržaj.
7. Nalazimo se u eri prije Semrusha: alati još nemaju infrastrukturu
Još uvijek smo u eri prije Semrush/Moz/Ahrefs za LLM. Danas nitko nema potpun uvid u utjecaj LLM-a na svoje poslovanje. Budite oprezni s bilo kojim dobavljačem ili konzultantom koji obećava potpunu vidljivost, jer to jednostavno još nije moguće. Trenutačne podatke praćenja treba tretirati kao smjerne i korisne za odluke, ali ne kao konačne.
Najbolje prakse generativne optimizacije motora: Što učiniti umjesto toga
Brza glasnoća je jedan od mnogih signala, a trenutno je jedan od slabijih. Ovdje su najbolje prakse generativne optimizacije motora koje zapravo vrijede.
Počnite sa svojim ICP-om, a ne s nadzornom pločom
Umjesto da dopustite da procijenjeni brzi volumen diktira vaše prioritete GEO sadržaja, počnite s onim što zapravo znate o svojoj publici. Najjači signal koji imate je vaš profil idealnog kupca. Za rješavanje kojih vas problema angažiraju vaši najbolji kupci? Koji jezik koriste za opis tih problema? Te bolne točke, a ne dobavljačeve modelirane brze procjene, trebale bi biti temelj onoga za što optimizirate odgovore umjetne inteligencije.
Izvor: The Smarketers
Ako ste obavili solidan ICP posao, već imate bolje podatke od onih koje vam može dati bilo koji alat za brzi volumen.
Idite tamo gdje vaša publika već govori
Uključite se u istraživanje stvarne publike tako što ćete otići tamo gdje vaša publika govori otvoreno i iskreno. Teme na Redditu, specijalizirani forumi, komentari na LinkedInu, Slack zajednice i stranice s recenzijama kao što su G2 i Trustpilot mjesta su gdje ljudi postavljaju nefiltrirana pitanja vlastitim riječima. To je upravo ona vrsta prirodnog jezika koja se blisko preslikava na način na koji bi netko zatražio AI alat. Ako se vaš ICP opetovano pita "kako mogu opravdati ROI X-a svom financijskom direktoru" na subredditu, to je daleko pouzdaniji sažetak sadržaja od brzog broja volumena priloženog upitu koji je odredio dobavljač.
Iskopajte vlastite razgovore s klijentima
Timovi okrenuti klijentima jedan su od najnedovoljnije korištenih izvora GEO inteligencije. Snimke prodajnih poziva, ulaznice za podršku, intervjui s klijentima i razgovori o uključivanju bogati su točnim izrazima koje pravi kupci koriste kada su zapeli, skeptični ili procjenjuju opcije. Taj jezik pripada vašem sadržaju i konačno odgovorima umjetne inteligencije. Ako vaš prodajni tim čuje isti prigovor svaki tjedan, postoji dobra šansa da netko AI postavlja isto pitanje.
Grupirajte i organizirajte upute oko jezika vaše publike
Nakon što dobijete sirovi unos iz svog ICP rada, foruma i razgovora s kupcima, sljedeći korak je njegovo strukturiranje. Umjesto da svaki potencijalni upit tretirate kao izoliranu metu, grupirajte ih prema namjeri i temi.
Brzo grupiranje oko sličnih tema ili bolnih točaka pomaže vam da vidite obrasce u tome kako vaša publika razmišlja o problemu, a ne samo kako formulira jedno pitanje. Grupa oko "kako izmjeriti GEO uspjeh" može uključivati upute o mjernim podacima, izvješćivanju, komunikaciji s dionicima i uspoređivanju. Svaki od njih zaslužuje sadržaj, a preklapanje između njih govori vam što bi trebao biti vaš temeljni narativ.
Ovo je značajan pomak odlogika istraživanja ključnih riječi. Kada razmišljate o GEO naspram AEO, organizacijski princip ostaje isti: tematski autoritet oko problema koje vaša publika pokušava riješiti. Brza organizacija prema namjeri i temi ono je što vam omogućuje sustavnu izgradnju tog autoriteta.
Koristite alate za brzu glasnoću za ono u čemu su zapravo dobri
Ništa od ovoga ne znači potpuno napuštanje platformi kao što su Profound ili Writesonic. Ako se pravilno koriste, oni su istinski korisni za usmjeravanje svijesti: uočavanje praznina u temama, praćenje pojavljuje li se vaš brend u pravim razgovorima i praćenje udjela glasa u odnosu na konkurente tijekom vremena.
Izvor
Pogreška je što ih koristite kao zamjenu za volumen ključne riječi i dopuštate da njihove procjene pokreću ono što stvarate. Neka vam vaš ICP, istraživanje publike i stvarni razgovori s korisnicima kažu za što optimizirati. Zatim upotrijebite brze podatke o volumenu za testiranje tlaka i nadzor, a ne za odlučivanje.
Napravite raspored praćenja koji stvarno funkcionira
S obzirom na to koliki je pomak citata u rezultatima umjetne inteligencije, praćenje treba biti strukturirano i dosljedno, a ne reaktivno. Provjera AI vidljivosti vašeg brenda jednom u kvartalu nije dovoljna. Mjesečni raspored praćenja za vaše glavne klastere brzih informacija daje vam razumnu osnovu za uočavanje značajnih pomaka bez pretjeranog indeksiranja buke.
Evo kako tome praktično pristupiti. Postavite definirani popis od 20 do 30 upita koji odražavaju najčešća pitanja vašeg ICP-a. Pokrenite ih određenom brzinom, barem jednom mjesečno, na platformama koje vaša publika najviše koristi, kao što su ChatGPT, Perplexity i Google AI Overviews. Pratite pojavljuju li se vaš brend, vaš sadržaj ili vaši konkurenti. Zabilježite promjene, ali nemojte pretjerano reagirati na jednomjesečne promjene s obzirom na to koliko varijacija postoji. Ono što gledate su usmjereni trendovi tijekom tri do šest mjeseci, a ne pozicije iz tjedna u tjedan.
To je ono što razdvaja timove sa stvarnom AI strategijom optimizacije pretraživanja od onih koji reagiraju na upozorenja nadzorne ploče. Praćenje informira; ne odlučuje.
Suština
Glasnoća upita pokušava približno prilagoditi potražnju kojoj možda već imate izravan pristup. Marke koje pobjeđuju u AI pretraživanju nisu one koje jure za upitima koji se najviše prate. Oni su ti koji razumiju svoju publiku dovoljno duboko da se pojave u odgovorima koje njihovi kupci zapravo traže.
