Большинство рекомендаций по оптимизации генеративного механизма начинаются с одного и того же: найдите подсказки, которые люди используют с инструментами искусственного интеллекта, отследите, какие из них обеспечивают узнаваемость вашего бренда, и создайте контент на основе запросов с наибольшим объемом.
Проблема? Эти данные в основном оценочные.
Генеративная оптимизация двигателей (GEO) все еще достаточно нова, поэтому инфраструктуры для ее точного измерения еще не существует. Подумайте, чем GEO отличается от SEO: на разработку зрелых и надежных сигналов, которые вы ожидаете от таких инструментов, как Semrush или Ahrefs, ушли годы. Измерение GEO еще не существует. То, что платформы называют «мгновенным объемом», моделируется, оценивается и часто является ошибочным.
В этом посте объясняется, почему объем запросов является ненадежной основой для вашей стратегии GEO и что вместо этого делают наиболее эффективные команды.
Ключевые выводы
«Предполагаемый объем» — это смоделированная оценка, а не фактические пользовательские данные, что делает его ненадежной отправной точкой для принятия решений по ГЕО.
Поведение ИИ непоследовательно; люди формулируют подсказки по-разному, а модели дают разные ответы, из-за чего шаблонам трудно доверять в небольших масштабах.
«Рейтинги» ИИ нестабильны; исследования показывают, что результаты постоянно меняются, поэтому отслеживание позиции так же, как вы отслеживаете SEO, не работает.
Большинство источников данных, будь то панели или API, предвзяты или не отражают реальное поведение пользователей в инструментах ИИ.
Отклонение цитирования велико, что означает, что источники и видимость меняются от месяца к месяцу даже для одинаковых запросов.
Инструменты GEO все еще являются ранними и направленными, но не окончательными; относитесь к ним соответственно.
Кластеризация подсказок на основе фактического языка вашего ICP превосходит поиск по спискам запросов, созданным поставщиком.
Последовательный график мониторинга имеет большее значение, чем просто зацикленность на какой-то одной точке данных.
Почему быстрый объем вводит в заблуждение вашу стратегию GEO
1. У LLM нет объема поиска: он оценивается, а не измеряется
Самая фундаментальная проблема заключается в том, что не существует настоящего «объема поиска ИИ», каким Google предоставляет данные поисковых запросов. LLM не публикуют эквиваленты частоты запросов или объема поиска. Their responses vary, sometimes subtly and sometimes dramatically, even for identical queries, due to probabilistic decoding and prompt context. Они также зависят от скрытых контекстных функций, таких как история пользователя, состояние сеанса и внедрения, которые непрозрачны для внешних наблюдателей. То, что платформы продают как «оперативный объем», — это смоделированная оценка, а не прямое измерение.
2. Ответы LLM недетерминированы по своей природе
Традиционный объем ключевых слов работает, потому что миллионы людей вводят одну и ту же фразу в Google, и эти запросы регистрируются. Взаимодействия ИИ принципиально отличаются. Поисковое поведение в традиционном SEO повторяется: миллионы одинаковых фраз обеспечивают стабильные показатели объема. Взаимодействия LLM являются разговорными и разнообразными. Люди по-разному перефразируют вопросы, часто в течение одного сеанса, что затрудняет распознавание образов при работе с небольшими наборами данных.
Этот недетерминизм заложен в том, как работают LLM. Они создают текст, используя вероятностные методы, выбирая слова на основе их вероятности, а не следуя установленному шаблону. Одна и та же подсказка может давать разные ответы, что затрудняет получение последовательных и точных выводов.
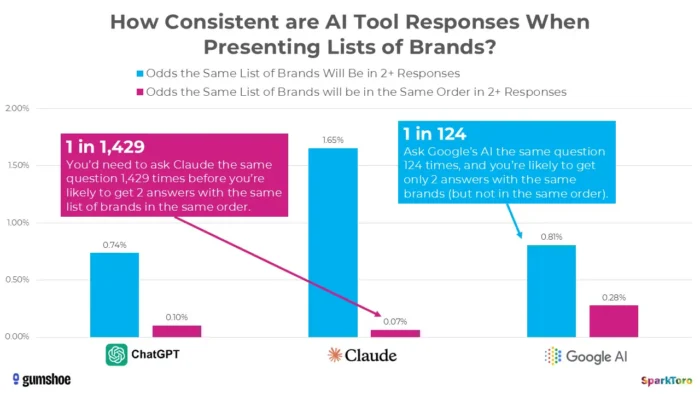
3. Исследование SparkToro показывает, что рейтинги по сути случайны.
Наиболее убедительные доказательства получены в знаковом исследовании Рэнда Фишкина и Gumshoe.ai, проведенном в январе 2026 года. Они протестировали 2961 приглашение у 600 добровольцев в ChatGPT, Claude и Google AI. Вывод: вероятность получения одного и того же списка брендов в любых двух ответах составляет менее одного из 100, а вероятность получения одного и того же списка в одном и том же порядке — менее одного из 1000. Как прямо заключил Фишкин, любой инструмент, который обеспечивает «рейтинговую позицию в сфере ИИ», по сути, ее выдумывает.
Источник
Research from SparkToro highlights significant variability in AI-generated brand recommendations even when identical prompts are used, suggesting that point-in-time AI visibility measurements may reflect volatility rather than durable performance signals.
4. Методологии, основанной на экспертных группах, свойственны проблемы предвзятости
Такие платформы, как Profound, полагаются на добровольные потребительские панели для получения оперативных данных. Углубленное лицензирует общение с несколькими потребительскими панелями с двойной подпиской, состоящими из реальных пользователей системы ответов, с масштабом в сотни миллионов запросов в месяц и применяет расширенное вероятностное моделирование для экстраполяции частоты, намерений и настроений в более широком масштабе.населения.
Источник
Хотя это звучит убедительно, добровольный характер этих панелей означает, что выборка может быть смещена в сторону более технически подкованных и заинтересованных пользователей, а не репрезентативного сечения того, как население в целом на самом деле предлагает инструменты ИИ.
5. API Queries Don’t Reflect Real Human Behavior
Многие инструменты запрашивают модели ИИ через API, чтобы имитировать подсказки пользователя, но это создает еще один пробел. Большинство инструментов отслеживания ИИ полагаются на вызовы API, а не на имитацию использования человеческого интерфейса, и ранние исследования показывают, что результаты API могут отличаться от результатов интерфейса, хотя масштабы и последствия этих различий требуют дальнейшего изучения. Природа запроса данных, ориентированная на API, также означает, что результаты не соответствуют тому, что на самом деле ищут люди.
6. Дрейф цитирования огромен и непредсказуем
Даже если вы проигнорируете все вышеперечисленное, ежемесячная стабильность цитируемости ИИ шокирующе низка. В исследовании Profound измерялось отклонение цитирования от месяца к месяцу и наблюдались очень большие изменения в цитируемых доменах даже для одинаковых запросов. Обзоры Google AI и ChatGPT показали ежемесячные колебания в десятки процентных пунктов.
Источник
Это означает, что «объем», указанный в любом задании сегодня, может выглядеть совершенно иначе в следующем месяце, что делает его ненадежной основой для решений об инвестировании в контент.
7. Мы живем в эпоху, предшествовавшую семрашу: инструменты еще не имеют инфраструктуры
Для программ магистратуры мы все еще живем в эпоху, когда еще не было Semrush/Moz/Ahrefs. Сегодня никто не имеет полного представления о влиянии LLM на их бизнес. Будьте осторожны с любым поставщиком или консультантом, обещающим полную прозрачность, потому что это пока просто невозможно. Текущие данные отслеживания следует рассматривать как направляющие и полезные для принятия решений, но не окончательные.
Лучшие практики генеративной оптимизации двигателя: что делать вместо этого
Оперативный объем — один из многих сигналов, и на данный момент он один из самых слабых. Вот лучшие практики генеративной оптимизации двигателей, которые действительно актуальны.
Начните со своего ПМС, а не с информационной панели
Вместо того, чтобы позволять предполагаемому объему запросов диктовать приоритеты вашего ГЕО-контента, начните с того, что вы на самом деле знаете о своей аудитории. Самый сильный сигнал, который у вас есть, — это ваш профиль идеального клиента. Для решения каких проблем ваши лучшие клиенты нанимают вас? Какой язык они используют для описания этих проблем? Эти болевые точки, а не смоделированные оперативные оценки поставщика, должны быть основой того, что вы оптимизируете в ответах ИИ.
Источник: Smarketers.
Если вы проделали серьезную работу по ICP, вы уже имеете более качественные данные, чем любой инструмент оперативного объема.
Go Where Your Audience Already Talks
Проведите исследование реальной аудитории, обращаясь туда, где ваша аудитория говорит открыто и честно. Темы Reddit, нишевые форумы, комментарии LinkedIn, сообщества Slack и сайты обзоров, такие как G2 и Trustpilot, — это места, где люди задают неотфильтрованные вопросы своими словами. Это именно тот естественный язык, который тесно связан с тем, как кто-то подсказывает инструмент искусственного интеллекта. Если ваш ICP постоянно спрашивает «как мне обосновать рентабельность инвестиций X для моего финансового директора» в субреддите, это гораздо более надежный краткий обзор контента, чем номер тома, прикрепленный к запросу, курируемому поставщиком.
Изучите свои собственные разговоры с клиентами
Команды, работающие с клиентами, являются одним из наиболее малоиспользуемых источников геоинформационной информации. Записи звонков по продажам, заявки в службу поддержки, интервью с клиентами и вводные беседы богаты точными формулировками, которые реальные покупатели используют, когда они застряли, скептически относятся или оценивают варианты. Этот язык принадлежит вашему контенту и, в конечном итоге, ответам ИИ. Если ваш отдел продаж каждую неделю слышит одно и то же возражение, велика вероятность, что кто-то задаст ИИ тот же вопрос.
Группируйте и организуйте подсказки на языке вашей аудитории
Как только вы получите необработанные данные от вашей работы по ICP, форумов и разговоров с клиентами, следующим шагом будет их структурирование. Вместо того, чтобы рассматривать каждую потенциальную подсказку как отдельную цель, сгруппируйте их по намерению и теме.
Prompt clustering around similar topics or pain points helps you see patterns in how your audience thinks about a problem, not just how they phrase a single question. Кластер «Как измерить успех ГЕО» может включать подсказки о показателях, отчетности, взаимодействии с заинтересованными сторонами и сравнительном анализе. Каждый из них заслуживает содержания, и совпадение между ними подскажет вам, каким должно быть ваше основное повествование.
Это значимый переход отлогика исследования ключевых слов. Когда вы думаете о GEO и AEO, принцип организации остается тем же: актуальный авторитет в отношении проблем, которые пытается решить ваша аудитория. Быстрая организация по намерениям и темам – это то, что позволяет вам систематически укреплять этот авторитет.
Используйте инструменты Prompt Volume для того, в чем они действительно хороши
Ничто из этого не означает полного отказа от таких платформ, как Profound или Writesonic. При правильном использовании они действительно полезны для направленной осведомленности: выявляют пробелы в темах, отслеживают, появляется ли ваш бренд в нужных разговорах, и отслеживают долю голоса конкурентов с течением времени.
Источник
Ошибка заключается в том, чтобы использовать их в качестве заменителя объема ключевых слов и позволять их оценкам определять то, что вы создаете. Пусть ваш ICP, исследование аудитории и реальные разговоры с клиентами подскажут вам, для чего оптимизировать. Затем используйте быстрые данные об объемах для проверки давления и мониторинга, а не для принятия решения.
Создайте график мониторинга, который действительно работает
Учитывая, насколько велика разница в цитировании результатов ИИ, мониторинг должен быть структурированным и последовательным, а не реактивным. Проверять видимость ИИ вашего бренда раз в квартал недостаточно. Ежемесячный график мониторинга основных кластеров подсказок дает вам разумную основу для выявления значимых изменений без чрезмерного индексирования шума.
Вот как подойти к этому практически. Создайте определенный список из 20–30 подсказок, отражающих наиболее распространенные вопросы вашего ПЦП. Запускайте их с установленной периодичностью, по крайней мере, ежемесячно, на платформах, которые ваша аудитория использует чаще всего, таких как ChatGPT, Perplexity и обзоры Google AI. Отслеживайте, появляется ли ваш бренд, ваш контент или ваши конкуренты. Отмечайте изменения, но не реагируйте слишком остро на месячные колебания, учитывая, насколько велики различия. Вы следите за направленными тенденциями в течение трех-шести месяцев, а не за еженедельными позициями.
Это то, что отличает команды с реальной стратегией поисковой оптимизации с помощью ИИ от тех, кто реагирует на предупреждения на информационной панели. Мониторинг информирует; это не решает.
Итог
Prompt volume tries to approximate demand that you may already have direct access to. Бренды, которые выигрывают в поиске с помощью ИИ, не гонятся за наиболее отслеживаемыми подсказками. Именно они понимают свою аудиторию достаточно глубоко, чтобы найти ответы, которые на самом деле ищут их клиенты.
