Повеќето совети за генеративните најдобри практики за оптимизација на моторот започнуваат на истото место: пронајдете ги инструкциите што луѓето ги користат со алатките за вештачка интелигенција, следете кои од нив даваат видливост на вашиот бренд и изградете содржина околу барањата со најголем обем.
Проблемот? Тие податоци во голема мера се проценети.
Генеративната оптимизација на моторот (ГЕО) сè уште е доволно нова што сè уште не постои инфраструктура за прецизно мерење. Размислете како GEO се разликува од SEO: зрелите, сигурни сигнали што ги очекувавте од алатките како Semrush или Ahrefs беа потребни години за да се развијат. ГЕО мерењето сè уште не е таму. Она што платформите го нарекуваат „промпт волумен“ е моделирано, проценето и често погрешно во насока.
Оваа објава објаснува зошто брзиот волумен е несигурна основа за вашата ГЕО стратегија и што прават наместо тоа тимовите со најдобри перформанси.
Клучни производи за носење
„Промпт волумен“ е моделирана проценка, а не вистински кориснички податоци, што го прави несигурна почетна точка за ГЕО одлуки.
Однесувањето на вештачката интелигенција е неконзистентно; луѓето ги поттикнуваат фразите поинаку, а моделите враќаат различни одговори, со што е тешко да се верува на шаблоните во мал обем.
„Рангирањето“ на вештачката интелигенција е нестабилно; Студиите покажуваат дека резултатите постојано се менуваат, така што следењето на позицијата на начинот на кој го следите SEO не се преведува.
Повеќето извори на податоци, без разлика дали се панели или API, се пристрасни или не го одразуваат вистинското однесување на корисниците во алатките за вештачка интелигенција.
Пренесувањето на наводите е големо, што значи дека изворите и видливоста се менуваат од месец во месец дури и за идентични известувања.
ГЕО алатките се сè уште рани и насочени, не се дефинитивни; третирајте ги соодветно.
Потсетите за кластерирање околу вистинскиот јазик на вашиот ICP ги надминуваат бркањето списоци со прашања подредени од продавачот.
Конзистентен распоред за следење е важен повеќе од опседнување со која било поединечна точка на податоци.
Зошто промптниот волумен ја доведува во заблуда вашата ГЕО стратегија
1. LLM немаат обем на пребарување: се проценува, не се мери
Најфундаменталниот проблем е тоа што не постои вистински „обем на пребарување со вештачка интелигенција“ како што Google ги изложува податоците за барањето за пребарување. LLM не објавуваат еквиваленти на фреквенција на барања или обем на пребарување. Нивните одговори се разликуваат, понекогаш суптилно, а понекогаш драматично, дури и за идентични прашања, поради веројатностичко декодирање и брз контекст. Тие исто така зависат од скриените контекстуални карактеристики како што се историјата на корисникот, состојбата на сесијата и вградувањата кои се непроѕирни за надворешни набљудувачи. Она што платформите го продаваат како „промптен волумен“ е моделирана проценка, а не директно мерење.
2. Одговорите на LLM се недетерминистички по природа
Традиционалниот волумен на клучни зборови функционира затоа што милиони луѓе ја пишуваат истата фраза во Google и тие прашања се евидентирани. Интеракциите со вештачка интелигенција се фундаментално различни. Однесувањето на пребарувањето во традиционалното оптимизација се повторува, со милиони идентични фрази кои водат стабилна метрика на волуменот. LLM интеракциите се разговорни и променливи. Луѓето ги преформулираат прашањата поинаку, често во рамките на една сесија, што го отежнува препознавањето на шаблоните со мали збирки на податоци.
Овој недетерминизам се впива во тоа како функционираат LLM. Тие произведуваат текст користејќи веројатни методи, избирајќи зборови врз основа на нивната веројатност, наместо да следат одредена шема. Истото барање може да произведе различни одговори, што го отежнува донесувањето конзистентни и точни заклучоци.
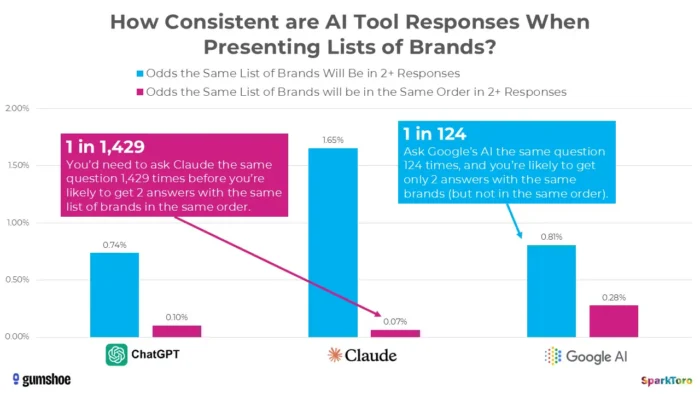
3. Истражувањето на SparkToro покажува дека рангирањето е суштински случајно
Најубедливиот доказ доаѓа од значајната студија од јануари 2026 година на Ранд Фишкин и Gumshoe.ai. Тие тестираа 2.961 потсетници на 600 волонтери на ChatGPT, Claude и Google AI. Наод: има помалку од една од 100 шанси да се добие иста листа на брендови во кои било два одговори и помалку од една од 1.000 шанси за иста листа по ист редослед. Како што отворено заклучи Фишкин, секоја алатка која дава „рангирана позиција во вештачката интелигенција“ во суштина ја сочинува.
Извор
Истражувањето од SparkToro нагласува значајна варијабилност во препораките за брендови генерирани со вештачка интелигенција дури и кога се користат идентични предупредувања, што сугерира дека мерењата на видливоста на вештачката интелигенција точка-во-време може да ја одразуваат нестабилноста, а не трајните сигнали за изведба.
4. Методологијата базирана на панели има инхерентни проблеми со пристрасност
Платформите како Профунд се потпираат на табли за потрошувачи кои се определуваат за да ги набават нивните брзи податоци. Длабоко лиценцира разговори од повеќекратни, двојни потрошувачки панели на вистински корисници на одговор, со размер од стотици милиони потсетници месечно и применува напредно веројатносно моделирање за екстраполирање на фреквенцијата, намерите и чувствата на поширокопопулации.
Извор
Иако ова звучи стабилно, природата на овие панели значи дека примерокот може да се сврти кон повеќе технолошки, ангажирани корисници, а не кон репрезентативен пресек за тоа како општата популација всушност ги поттикнува алатките за вештачка интелигенција.
5. Прашањата за API не го одразуваат вистинското човечко однесување
Многу алатки ги прашуваат моделите на вештачка интелигенција преку API за да симулираат инструкции од корисниците, но ова воведува уште една празнина. Повеќето алатки за следење на вештачката интелигенција се потпираат на повици на API наместо да имитираат употреба на човечки интерфејс, а раните истражувања сугерираат дека резултатите од API може да се разликуваат од резултатите од интерфејсот, иако големината и импликациите на овие разлики бараат дополнително истражување. Природата на податоците за пребарување фокусирани на API значи дека резултатите не се усогласени со она што луѓето всушност го бараат.
6. Наведувањето на наводите е масовно и непредвидливо
Дури и ако игнорирате сè погоре, стабилноста од месец до месец на наводите на вештачката интелигенција е шокантно ниска. Студијата на Профунд го мери движењето на наводите од месец во месец и забележа многу големи промени во наведените домени дури и за идентични барања. Прегледите на Google AI и ChatGPT покажаа месечни варијации од десетици процентни поени.
Извор
Ова значи дека „волуменот“ прикачен на кое било дадено барање денес може да изгледа сосема поинаку следниот месец, што го прави несигурна основа за одлуки за инвестирање во содржината.
7. Ние сме во пред-семруш ера: Алатките сè уште немаат инфраструктура
Сè уште сме во ера пред Семруш/Моз/Ахрефс за LLM. Никој нема целосна видливост на влијанието на LLM врз нивниот бизнис денес. Внимавајте на кој било продавач или консултант кој ветува целосна видливост, бидејќи тоа едноставно сè уште не е можно. Тековните податоци за следење треба да се третираат како насочени и корисни за одлуки, но не и конечни.
Најдобри практики за генеративна оптимизација на моторот: што да правите наместо тоа
Брзата јачина на звукот е еден сигнал меѓу многуте, а во моментов е еден од послабите. Еве ги генеративните најдобри практики за оптимизација на моторот што всушност стојат.
Започнете со вашиот ICP, а не со контролна табла
Наместо да дозволите проценетиот брз волумен да ги диктира вашите приоритети на ГЕО содржината, започнете со она што всушност го знаете за вашата публика. Најсилниот сигнал што го имате е вашиот Идеален профил на клиент. Кои проблеми ве ангажираат вашите најдобри клиенти да ги решите? Кој јазик го користат за да ги опишат тие проблеми? Тие точки на болка, а не моделирани брзи проценки на продавачот, треба да бидат основата на она за што го оптимизирате во одговорите на вештачката интелигенција.
Извор: The Smarketers
Ако сте завршиле солидна работа на ICP, веќе имате подобри податоци отколку што може да ви даде која било алатка за брза јачина на звук.
Одете таму каде што вашата публика веќе зборува
Обложете се во вистинското истражување на публиката така што ќе одите таму каде што вашата публика зборува отворено и искрено. Нишките на Reddit, нишните форуми, коментарите на LinkedIn, Slack заедниците и страниците за прегледи како G2 и Trustpilot се места каде што луѓето поставуваат нефилтрирани прашања со свои зборови. Токму таков природен јазик е блиску до израз како некој би поттикнал алатка за вештачка интелигенција. Ако вашиот ICP постојано прашува „како да го оправдам рентабилноста на X на мојот финансиски директор“ во подредит, тоа е многу посигурен кус за содржина отколку брз број за волумен прикачен на барање подредено од продавачот.
Рудирајте ги вашите сопствени разговори со клиентите
Тимовите кои се соочуваат со клиенти се еден од најнеискористените извори на ГЕО интелигенција. Снимките од продажните повици, билетите за поддршка, интервјуата со клиентите и разговорите за приклучување се богати со точната фраза што ја користат вистинските купувачи кога се заглавени, скептични или ги оценуваат опциите. Тој јазик припаѓа во вашата содржина и на крајот на одговорите со вештачка интелигенција. Ако вашиот тим за продажба го слуша истиот приговор секоја недела, голема е шансата некој да му го поставува истото прашање на вештачка интелигенција.
Групирајте и организирајте ги потсетниците околу јазикот на вашата публика
Откако ќе добиете необработени информации од вашата работа на ICP, форумите и разговорите со клиентите, следниот чекор е негово структурирање. Наместо да го третирате секое потенцијално известување како изолирана цел, групирајте ги по намера и тема.
Брзото групирање околу слични теми или точки на болка ви помага да видите модели во тоа како вашата публика размислува за некој проблем, а не само како формулира едно прашање. Кластерот околу „како да се измери успехот на ГЕО“ може да вклучува инструкции за метрика, известување, комуникација со засегнатите страни и бенчмаркинг. Секој од нив заслужува содржина, а преклопувањето меѓу нив ви кажува каква треба да биде вашата основна наративност.
Ова е значајна промена одлогика за истражување на клучни зборови. Кога размислувате за ГЕО наспроти ОЕО, принципот на организација останува ист: тематски авторитет околу проблемите што вашата публика се обидува да ги реши. Навремената организација по намера и тема е она што ви овозможува систематски да го изградите тој авторитет.
Користете ги алатките за брза јачина на звук за она во што всушност се добри
Ништо од ова не значи целосно напуштање на платформите како Profound или Writesonic. Ако се користат правилно, тие се навистина корисни за свесност за насочување: воочување на празнините во темата, следење дали вашиот бренд се појавува во вистинските разговори и следење на уделот на гласот во однос на конкурентите со текот на времето.
Извор
Грешката е што ги користите како замена за обемот на клучни зборови и дозволувате нивните проценки да го поттикнат она што го создавате. Дозволете вашиот ICP, истражувањето на публиката и вистинските разговори со клиентите да ви кажат за што да оптимизирате. Потоа користете брзи податоци за јачината на звукот за тестирање на притисок и следење, а не за да одлучувате.
Направете распоред за следење што навистина функционира
Со оглед на колкаво движење на наводите постои во излезите на вештачката интелигенција, следењето треба да биде структурирано и конзистентно наместо реактивно. Проверувањето на видливоста на вештачката интелигенција на вашиот бренд еднаш четвртина не е доволно. Месечниот распоред за следење за вашите основни кластери за брзи информации ви дава разумна основа за забележување значајни поместувања без прекумерно индексирање на бучавата.
Еве како практично да му пристапите. Поставете дефинирана листа од 20 до 30 потсетници што ги одразуваат најчестите прашања на вашиот ICP. Извршете ги на одредена каденца, барем месечно, на платформите што најмногу ги користи вашата публика, како што се ChatGPT, Perplexity и Google AI Прегледи. Следете дали се појавува вашиот бренд, вашата содржина или вашите конкуренти. Забележете се менува, но не реагирајте претерано на едномесечните нишања со оглед на тоа колкава варијација постои. Она што го гледате се насочени трендови во текот на три до шест месеци, а не позиции од недела во недела.
Ова е она што ги одвојува тимовите со вистинска стратегија за оптимизација за пребарување со вештачка интелигенција од оние кои реагираат на предупредувањата на контролната табла. Мониторинг информира; тоа не одлучува.
Крајна линија
Јачината на звукот се обидува приближно да ја приближи побарувачката до која можеби веќе имате директен пристап. Брендовите што победуваат во пребарувањето со вештачка интелигенција не се оние кои ги бркаат барањата кои најмногу се следат. Тие се оние кои ја разбираат својата публика доволно длабоко за да се појават во одговорите што ги бараат нивните клиенти.
