Dauguma patarimų dėl generatyvaus variklio optimizavimo geriausios praktikos prasideda toje pačioje vietoje: raskite raginimus, kuriuos žmonės naudoja naudodami AI įrankius, stebėkite, kurie iš jų suteikia jūsų prekės ženklo matomumą, ir kurkite turinį pagal didžiausios apimties užklausas.
Problema? Šie duomenys iš esmės yra apskaičiuoti.
Generatyvusis variklio optimizavimas (GEO) vis dar pakankamai naujas, todėl infrastruktūros, kuri leistų jį tiksliai išmatuoti, dar nėra. Pagalvokite, kuo GEO skiriasi nuo SEO: brandiems, patikimiems signalams, kurių tikėjotės iš tokių įrankių kaip Semrush ar Ahrefs, sukurti prireikė metų. GEO matavimo dar nėra. Tai, ką platformos vadina „prompt volume“, yra modeliuojama, įvertinta ir dažnai neteisinga.
Šiame įraše paaiškinama, kodėl greita apimtis yra nepatikimas jūsų GEO strategijos pagrindas ir ką veikia geriausios komandos.
Key Takeaways
„Prompt volume“ yra sumodeliuotas įvertinimas, o ne faktiniai naudotojo duomenys, todėl tai yra nepatikimas GEO sprendimų atskaitos taškas.
AI elgesys nenuoseklus; žmonės skirtingai suformuluoja raginimus, o modeliai pateikia įvairius atsakymus, todėl mažu mastu modeliais sunku pasitikėti.
AI „reitingai“ yra nestabilūs; tyrimai rodo, kad rezultatai nuolat kinta, todėl sekimo padėtis taip, kaip sekate SEO, nėra verčiama.
Dauguma duomenų šaltinių, nesvarbu, ar tai būtų skydai, ar API, yra šališki arba neatspindi tikrojo naudotojo elgesio AI įrankiuose.
Citavimo dreifas yra didelis, o tai reiškia, kad šaltiniai ir matomumas keičiasi kiekvieną mėnesį net ir identiškų raginimų atveju.
GEO įrankiai vis dar yra ankstyvi ir kryptingi, o ne galutiniai; atitinkamai elkitės su jais.
Klasterizacijos raginimai pagal tikrąją jūsų ICP kalbą pranoksta tiekėjų kuruojamų užklausų sąrašų sekimą.
Nuoseklus stebėjimo grafikas yra svarbesnis nei bet kurio vieno duomenų taško apsėstymas.
Kodėl greita apimtis klaidina jūsų GEO strategiją
1. LLM neturi paieškos apimties: ji apskaičiuota, o ne išmatuota
Esminė problema yra ta, kad nėra tikrosios „AI paieškos apimties“, kaip „Google“ pateikia paieškos užklausų duomenis. LLM neskelbia užklausų dažnumo ar paieškos apimties atitikmenų. Jų atsakymai skiriasi, kartais subtiliai, o kartais dramatiškai, net ir identiškų užklausų atveju dėl tikimybinio dekodavimo ir greito konteksto. Jie taip pat priklauso nuo paslėptų kontekstinių ypatybių, pvz., vartotojo istorijos, seanso būsenos ir išoriniams stebėtojams nepermatomų įterpimų. Tai, ką platformos parduoda kaip „sparčią apimtį“, yra sumodeliuotas įvertinimas, o ne tiesioginis matavimas.
2. LLM atsakymai iš prigimties nėra deterministiniai
Tradicinis raktinių žodžių kiekis veikia, nes milijonai žmonių įveda tą pačią frazę į „Google“ ir šios užklausos registruojamos. AI sąveika iš esmės skiriasi. Tradicinio SEO paieškos elgsena kartojasi, o milijonai identiškų frazių lemia stabilią apimties metriką. LLM sąveika yra pokalbio ir kintama. Žmonės perfrazuoja klausimus skirtingai, dažnai per vieną seansą, todėl modelio atpažinimas yra sunkesnis naudojant mažus duomenų rinkinius.
Šis nedeterminizmas yra susijęs su LLM darbo principu. Jie kuria tekstą naudodami tikimybinius metodus, pasirenka žodžius pagal jų tikimybę, o ne pagal nustatytą modelį. Tas pats raginimas gali sukelti skirtingus atsakymus, todėl sunku padaryti nuoseklias ir tikslias išvadas.
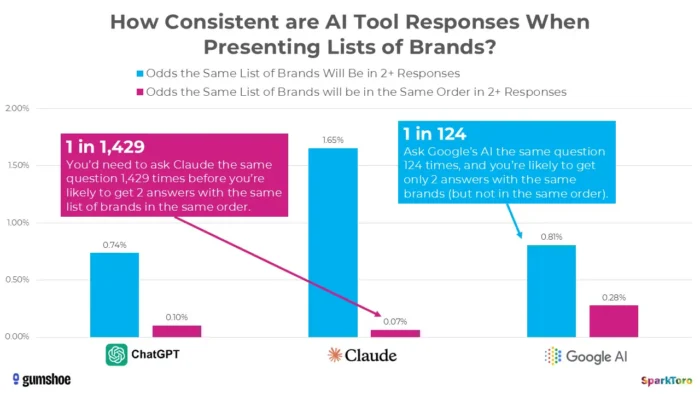
3. „SparkToro“ tyrimai rodo, kad reitingai iš esmės yra atsitiktiniai
Įtikinamiausi įrodymai gauti iš žymaus 2026 m. sausio mėn. Rando Fishkino ir Gumshoe.ai tyrimo. Jie išbandė 2 961 raginimą iš 600 savanorių „ChatGPT“, „Claude“ ir „Google AI“. Išvada: yra mažesnė nei viena iš 100 tikimybė gauti tą patį prekių ženklų sąrašą bet kuriuose dviejuose atsakymuose ir mažiau nei viena iš 1000 tikimybė, kad tas pats sąrašas bus ta pačia tvarka. Kaip tiesiai šviesiai padarė Fishkinas, bet koks įrankis, suteikiantis „reitingą AI“, iš esmės yra jį sugalvojęs.
Šaltinis
„SparkToro“ atliktas tyrimas atkreipia dėmesį į didelį dirbtinio intelekto sugeneruotų prekės ženklo rekomendacijų kintamumą, net kai naudojami identiški raginimai, o tai rodo, kad tam tikru momentu AI matomumo matavimai gali atspindėti nepastovumą, o ne ilgalaikius veikimo signalus.
4. Grupės pagrindu sukurta metodika turi būdingų šališkumo problemų
Tokios platformos kaip „Profound“ naudojasi pasirinktomis vartotojų grupėmis, kad gautų greitus duomenis. Nuodugniai licencijuoja pokalbius iš kelių, dvigubai pasirinktų tikrų atsakymų variklio vartotojų grupių, kurių mastas siekia šimtus milijonų raginimų per mėnesį, ir taiko pažangų tikimybinį modeliavimą, kad ekstrapoliuotų dažnumą, ketinimus ir nuotaikas plačiau.gyventojų.
Šaltinis
Nors tai skamba tvirtai, šių skydelių pasirinkimo pobūdis reiškia, kad pavyzdys gali būti nukreiptas link labiau techniką išmanančių, labiau įsitraukusių vartotojų, o ne reprezentatyvaus skerspjūvio, kaip plačioji populiacija iš tikrųjų ragina naudoti AI įrankius.
5. API užklausos neatspindi tikrojo žmogaus elgesio
Daugelis įrankių ieško AI modelių per API, kad imituotų vartotojo raginimus, tačiau tai sukuria dar vieną spragą. Dauguma AI sekimo įrankių remiasi API skambučiais, o ne imituoja žmogaus sąsajos naudojimą, o ankstyvieji tyrimai rodo, kad API rezultatai gali skirtis nuo sąsajos rezultatų, nors šių skirtumų mastą ir pasekmes reikia toliau tirti. Į API orientuotas duomenų užklausų pobūdis taip pat reiškia, kad rezultatai nesutampa su tuo, ko žmonės iš tikrųjų ieško.
6. Citavimo dreifas yra didžiulis ir nenuspėjamas
Net jei nepaisysite visko, kas išdėstyta aukščiau, mėnesinis AI šaltinių stabilumas yra šokiruojančiai mažas. „Profound“ atliktas tyrimas matavo citatų dreifą kiekvieną mėnesį ir pastebėjo labai didelius cituotų domenų pokyčius net ir identiškų raginimų atveju. „Google AI Overviews“ ir „ChatGPT“ rodė dešimčių procentinių punktų mėnesio svyravimus.
Šaltinis
Tai reiškia, kad šiandien prie bet kurio raginimo pridėtas „apimtis“ kitą mėnesį gali atrodyti visiškai kitaip, todėl tai bus nepatikimas pagrindas investavimo į turinį sprendimams.
7. Išgyvename erą prieš Semrushą: įrankiai dar neturi infrastruktūros
Mes vis dar esame iki Semrush / Moz / Ahrefs eros LLM. Šiandien niekas neturi visiško LLM poveikio jų verslui matomumo. Būkite atsargūs, kad pardavėjas ar konsultantas žada visišką matomumą, nes kol kas tai tiesiog neįmanoma. Dabartiniai stebėjimo duomenys turėtų būti traktuojami kaip nukreipiantys ir naudingi priimant sprendimus, bet ne galutiniai.
Generatyvaus variklio optimizavimo geriausia praktika: ką daryti vietoj to
Greitas garsumas yra vienas iš daugelio signalų, o šiuo metu jis yra vienas iš silpnesnių. Štai generatyvaus variklio optimizavimo geriausia praktika, kuri iš tikrųjų pasiteisina.
Pradėkite nuo savo ICP, o ne nuo prietaisų skydelio
Užuot leidę apskaičiuotam greito pranešimo kiekiui diktuoti jūsų GEO turinio prioritetus, pradėkite nuo to, ką iš tikrųjų žinote apie savo auditoriją. Stipriausias jūsų signalas yra idealaus kliento profilis. Kokioms problemoms spręsti geriausi jus samdantys klientai? Kokia kalba jie apibūdina tas problemas? Tie skausmo taškai, o ne pardavėjo sumodeliuoti greiti įverčiai, turėtų būti pagrindas tam, ką optimizuojate PG atsakymuose.
Šaltinis: The Smarketers
Jei atlikote rimtą ICP darbą, jau turite geresnių duomenų, nei gali suteikti bet koks greitas apimties įrankis.
Eikite ten, kur jau kalba jūsų auditorija
Atlikite realios auditorijos tyrimą eidami ten, kur jūsų auditorija kalba atvirai ir nuoširdžiai. „Reddit“ gijos, nišiniai forumai, „LinkedIn“ komentarai, „Slack“ bendruomenės ir apžvalgų svetainės, tokios kaip G2 ir „Trustpilot“, yra vietos, kur žmonės savais žodžiais užduoda nefiltruotus klausimus. Tai yra būtent tokia natūrali kalba, kuri glaudžiai siejasi su tuo, kaip kas nors paskatintų dirbtinio intelekto įrankį. Jei jūsų ICP nuolat klausia „kaip pateisinti X IG savo finansiniam direktoriui“, tai yra daug patikimesnis turinio trumpinys nei greitas apimties numeris, pridedamas prie pardavėjo kuruojamos užklausos.
Kurkite savo klientų pokalbius
Klientams skirtos komandos yra vienas iš labiausiai nepakankamai naudojamų GEO informacijos šaltinių. Pardavimo skambučių įrašuose, palaikymo bilietuose, klientų pokalbiuose ir įtraukiamuosiuose pokalbiuose gausu tikslių frazių, kurias naudoja tikrieji pirkėjai, kai jie yra įstrigę, skeptiškai vertina ar vertina galimybes. Ši kalba priklauso jūsų turiniui ir galiausiai AI atsakymams. Jei jūsų pardavimo komanda kiekvieną savaitę išgirsta tą patį prieštaravimą, yra didelė tikimybė, kad kas nors AI užduos tą patį klausimą.
Surinkite ir tvarkykite raginimus pagal auditorijos kalbą
Kai gausite neapdorotą informaciją iš savo ICP darbo, forumų ir pokalbių su klientais, kitas žingsnis yra jų struktūrizavimas. Užuot vertinę kiekvieną galimą raginimą kaip atskirą tikslą, sugrupuokite juos pagal ketinimą ir temą.
Greitas sugrupavimas aplink panašias temas ar skausmingus taškus padeda pamatyti, kaip jūsų auditorija galvoja apie problemą, o ne tik kaip jie suformuluoja vieną klausimą. Grupė apie „kaip įvertinti GEO sėkmę“ gali apimti raginimus apie metriką, ataskaitas, bendravimą su suinteresuotosiomis šalimis ir lyginamąją analizę. Kiekvienas iš jų nusipelno turinio, o jų sutapimas parodo, koks turėtų būti jūsų pagrindinis pasakojimas.
Tai prasmingas poslinkis nuoraktinių žodžių tyrimo logika. Kai galvojate apie GEO ir AEO, organizavimo principas išlieka tas pats: aktualus autoritetas, susijęs su problemomis, kurias bando išspręsti jūsų auditorija. Greitas organizavimas pagal tikslą ir temą yra tai, kas leidžia sistemingai kurti tą autoritetą.
Naudokite Prompt Volume Tools, ką jie iš tikrųjų yra geri
Visa tai nereiškia, kad reikia visiškai atsisakyti tokių platformų kaip „Profound“ ar „Writesonic“. Tinkamai naudojami, jie tikrai naudingi siekiant informuoti apie kryptį: pastebėti temų spragas, stebėti, ar jūsų prekės ženklas rodomas tinkamuose pokalbiuose, ir laikui bėgant stebėti konkurentų balso dalį.
Šaltinis
Klaida yra tai, kad jie naudojami kaip raktinių žodžių apimties pakaitalas ir leidžiami jų įvertinimai, lemiantys tai, ką sukuriate. Tegul jūsų ICP, auditorijos tyrimai ir tikri klientų pokalbiai nurodo, ką optimizuoti. Tada naudokite greitus apimties duomenis slėgiui išbandyti ir stebėti, o ne nuspręsti.
Sudarykite stebėjimo tvarkaraštį, kuris iš tikrųjų veikia
Atsižvelgiant į tai, kiek AI išvesties šaltinių yra, stebėjimas turi būti struktūrizuotas ir nuoseklus, o ne reaktyvus. Nepakanka kartą per ketvirtį patikrinti savo prekės ženklo AI matomumą. Mėnesinis pagrindinių raginimų grupių stebėjimo grafikas suteikia pagrįstą pradinį tašką reikšmingiems poslinkiams pastebėti be pernelyg didelio triukšmo indeksavimo.
Štai kaip tai padaryti praktiškai. Sudarykite apibrėžtą 20–30 raginimų sąrašą, atspindintį dažniausiai užduodamus ICP klausimus. Vykdykite juos nustatytu ritmu, bent kartą per mėnesį, platformose, kurias dažniausiai naudoja jūsų auditorija, pvz., „ChatGPT“, „Perplexity“ ir „Google AI Overviews“. Stebėkite, ar rodomas jūsų prekės ženklas, turinys ar konkurentai. Atkreipkite dėmesį į pokyčius, bet nepersistenkite į vieno mėnesio svyravimus, atsižvelgiant į tai, koks skirtumas yra. Tai, ką stebite, yra krypties tendencijos per tris ar šešis mėnesius, o ne kas savaitę.
Tai atskiria komandas, turinčias tikrą AI paieškos optimizavimo strategiją, nuo tų, kurios reaguoja į prietaisų skydelio įspėjimus. Monitoringas informuoja; tai neapsprendžia.
Esmė
Raginimo garsumas bando apytiksliai nustatyti poreikį, prie kurio jau galite turėti tiesioginę prieigą. Prekės ženklai, kurie laimi AI paieškoje, nėra tie, kurie persekioja dažniausiai stebimus raginimus. Jie yra tie, kurie pakankamai giliai supranta savo auditoriją, kad galėtų pasirodyti atsakymuose, kurių iš tikrųjų ieško jų klientai.
