Suurin osa generatiivisen moottorin optimoinnin parhaista käytännöistä alkaa samasta paikasta: etsi ihmisten käyttämät AI-työkalujen kehotteet, seuraa, mitkä antavat brändillesi näkyvyyttä, ja rakenna sisältöä suurimpien kyselyiden ympärille.
Ongelma? Nämä tiedot ovat suurelta osin arvioituja.
Generatiivinen moottorin optimointi (GEO) on vielä tarpeeksi uutta, joten infrastruktuuria sen tarkkaan mittaamiseen ei ole vielä olemassa. Ajattele, kuinka GEO eroaa SEO:sta: kypsät, luotettavat signaalit, joita olet tottunut odottamaan Semrushin tai Ahrefsin kaltaisilta työkaluilta, kesti vuosia kehittää. GEO-mittaus ei ole vielä olemassa. Se, mitä alustat kutsuvat "prompt volume"ksi, on mallinnettua, arvioitua ja usein suunnallisesti väärin.
Tässä viestissä kerrotaan, miksi nopea määrä on epäluotettava perusta GEO-strategiallesi ja mitä parhaiten menestyvät tiimit tekevät sen sijaan.
Key Takeaways
"Prompt volume" on mallinnettu arvio, ei todellista käyttäjädataa, joten se on epäluotettava lähtökohta GEO-päätöksille.
Tekoälykäyttäytyminen on epäjohdonmukaista; ihmiset ilmaisevat kehotteita eri tavalla ja mallit antavat erilaisia vastauksia, mikä tekee malleista vaikea luottaa pienessä mittakaavassa.
AI "sijoitukset" ovat epävakaita; tutkimukset osoittavat, että tulokset muuttuvat jatkuvasti, joten hakupaikan seuranta tavoilla, joilla seuraat hakukoneoptimointia, ei käänny.
Useimmat tietolähteet, olivatpa ne paneelit tai sovellusliittymät, ovat puolueellisia tai eivät heijasta todellista käyttäjien käyttäytymistä tekoälytyökaluissa.
Sitaattien ajautuminen on suuri, mikä tarkoittaa, että lähteet ja näkyvyys vaihtelevat kuukausittain jopa identtisten kehotteiden kohdalla.
GEO-työkalut ovat vielä varhaisia ja suuntaa antavia, eivät lopullisia; kohtele niitä sen mukaisesti.
Klusterointikehotteet ICP:si todellisen kielen ympärillä toimivat paremmin kuin toimittajan kuratoimien kyselyluetteloiden jahtaaminen.
Johdonmukaisella seuranta-aikataululla on enemmän merkitystä kuin yksittäisen datapisteen pakkomielle.
Miksi nopea määrä johtaa GEO-strategiaasi harhaan?
1. LLM:illä ei ole hakumäärää: se on arvioitu, ei mitattu
Perimmäisin ongelma on, että ei ole olemassa todellista "AI-hakumäärää", jollaista Google paljastaa hakukyselytiedot. LLM:t eivät julkaise kyselyn tiheyttä tai hakumäärän vastaavia. Heidän vastauksensa vaihtelevat, joskus hienovaraisesti ja joskus dramaattisesti, jopa identtisissä kyselyissä todennäköisyyspohjaisen dekoodauksen ja nopean kontekstin vuoksi. Ne riippuvat myös piilotetuista kontekstuaalisista ominaisuuksista, kuten käyttäjähistoriasta, istunnon tilasta ja upotuksista, jotka ovat läpinäkymättömiä ulkoisille tarkkailijoille. Se, mitä alustat myyvät "nopeutena volyyminä", on mallinnettu arvio, ei suora mittaus.
2. LLM-vastaukset ovat luonteeltaan epädeterministisiä
Perinteinen avainsanamäärä toimii, koska miljoonat ihmiset kirjoittavat saman lauseen Googleen ja kyselyt kirjataan. AI-vuorovaikutukset ovat pohjimmiltaan erilaisia. Hakukäyttäytyminen perinteisessä hakukoneoptimoinnissa on toistuvaa, ja miljoonat identtiset lauseet ohjaavat vakaita volyymimittauksia. LLM-vuorovaikutus on keskustelullista ja vaihtelevaa. Ihmiset muotoilevat kysymykset eri tavalla, usein yhden istunnon aikana, mikä tekee kuvioiden tunnistamisesta vaikeampaa pienillä tietojoukoilla.
Tämä epädeterminismi on juurtunut siihen, miten LLM:t toimivat. He tuottavat tekstiä todennäköisyysmenetelmillä ja valitsevat sanat niiden todennäköisyyden perusteella sen sijaan, että noudattavat asetettua kaavaa. Sama kehote voi tuottaa erilaisia vastauksia, mikä tekee johdonmukaisten ja tarkkojen johtopäätösten tekemisestä vaikeaa.
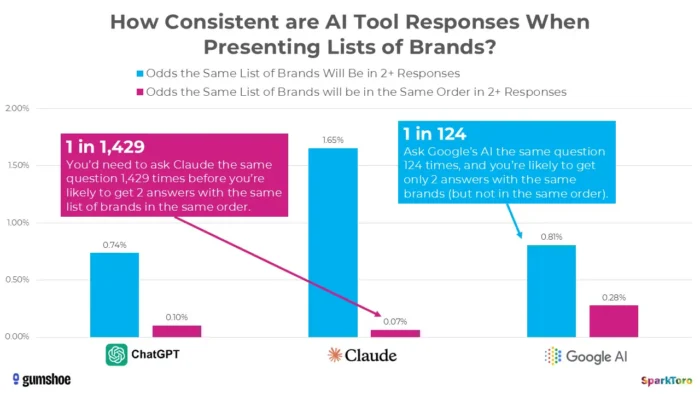
3. SparkToron tutkimus osoittaa, että sijoitukset ovat pohjimmiltaan satunnaisia
Vakuuttavin todiste on Rand Fishkinin ja Gumshoe.ai:n tammikuussa 2026 tekemästä maamerkkitutkimuksesta. He testasivat 2 961 kehotetta 600 ChatGPT:n, Clauden ja Google AI:n vapaaehtoisen kesken. Havainto: on vähemmän kuin yksi 100:sta todennäköisyys saada sama tuotemerkkiluettelo kahdessa vastauksessa ja vähemmän kuin yksi 1000:sta mahdollisuus samalle listalle samassa järjestyksessä. Kuten Fishkin suorasukaisesti totesi, kaikki työkalut, jotka antavat "sijoituspaikan tekoälyssä", muodostavat pohjimmiltaan sen.
lähde
SparkToron tutkimus korostaa merkittävää vaihtelua tekoälyn luomissa tuotemerkkisuosituksissa, vaikka käytettäisiin identtisiä kehotteita, mikä viittaa siihen, että ajankohtaiset tekoälyn näkyvyysmittaukset voivat heijastaa volatiliteettia kestävien suorituskykysignaalien sijaan.
4. Paneelipohjaisessa metodologiassa on luontaisia harhaongelmia
Profoundin kaltaiset alustat luottavat kuluttajapaneeleihin saadakseen nopeat tiedot. Syvällinen lisensoi keskustelut useilta, kaksoisvalmiilta kuluttajapaneeleilta todellisista vastauskoneen käyttäjistä satojen miljoonien kehotteiden skaalalla kuukaudessa ja käyttää kehittynyttä todennäköisyysmallinnusta taajuuden, tarkoituksen ja tunteen ekstrapoloimiseksi laajemmin.populaatiot.
lähde
Vaikka tämä kuulostaa vankalta, näiden paneelien osallistumisluonne tarkoittaa, että otos saattaa kääntyä kohti tekniikkataitoisia, sitoutuneempia käyttäjiä, ei edustavaa poikkileikkausta siitä, kuinka suuri yleisö todella kehottaa tekoälytyökaluja.
5. API-kyselyt eivät heijasta todellista ihmiskäyttäytymistä
Monet työkalut kyselevät tekoälymalleja API:n kautta simuloidakseen käyttäjän kehotteita, mutta tämä aiheuttaa toisen aukon. Useimmat tekoälyn seurantatyökalut luottavat API-kutsuihin sen sijaan, että ne matkisivat ihmisen käyttöliittymän käyttöä, ja varhaiset tutkimukset viittaavat siihen, että API-tulokset voivat poiketa käyttöliittymän tuloksista, vaikka näiden erojen suuruus ja vaikutukset vaativat lisätutkimuksia. Tietojen kyselyn API-keskeinen luonne tarkoittaa myös sitä, että tulokset eivät vastaa sitä, mitä ihmiset todella etsivät.
6. Citation Drift on valtava ja arvaamaton
Vaikka jättäisit huomioimatta kaiken yllä olevan, AI-viitteiden kuukausittainen vakaus on järkyttävän alhainen. Profoundin tutkimus mittasi viittausten siirtymistä kuukausittain ja havaitsi erittäin suuria muutoksia lainatuissa verkkotunnuksissa jopa identtisten kehotteiden kohdalla. Google AI Overviews ja ChatGPT osoittivat kymmenien prosenttiyksiköiden kuukausittaiset vaihtelut.
lähde
Tämä tarkoittaa, että mihin tahansa kehotteeseen liitetty "volyymi" voi näyttää täysin erilaiselta ensi kuussa, mikä tekee siitä epäluotettavan perustan sisältösijoituspäätöksille.
7. Elämme Semrushia edeltävää aikakautta: työkaluilla ei vielä ole infrastruktuuria
Elämme edelleen Semrushia/Mozia/Ahrefsia edeltävää aikakautta LLM:n osalta. Kenelläkään ei ole täydellistä näkyvyyttä LLM:n vaikutuksesta liiketoimintaansa tänään. Varo myyjää tai konsulttia, joka lupaa täydellistä näkyvyyttä, koska se ei yksinkertaisesti ole vielä mahdollista. Nykyisiä seurantatietoja tulee käsitellä suuntaa antavina ja hyödyllisinä päätöksiä tehtäessä, mutta ei lopullisia.
Generatiivisen moottorin optimoinnin parhaat käytännöt: Mitä tehdä sen sijaan
Nopea äänenvoimakkuus on yksi signaali monien joukossa, ja tällä hetkellä se on yksi heikoimmista. Tässä ovat generatiivisen moottorin optimoinnin parhaat käytännöt, jotka todella kestävät.
Aloita ICP:stäsi, ei kojelautasta
Sen sijaan, että antaisit arvioitujen kehotteiden määrän sanella GEO-sisältöprioriteettisi, aloita siitä, mitä todella tiedät yleisöstäsi. Vahvin signaalisi on ihanteellinen asiakasprofiilisi. Mitä ongelmia parhaat asiakkaasi, jotka palkkaavat sinut, ratkaisemaan? Mitä kieltä he käyttävät kuvaillessaan näitä ongelmia? Näiden kipupisteiden, ei toimittajan mallintamien nopean arvioiden, pitäisi olla perusta sille, mitä optimoit tekoälyvastauksissa.
Lähde: The Smarketers
Jos olet tehnyt vankkaa ICP-työtä, sinulla on jo parempia tietoja kuin mikään nopea volyymityökalu voi antaa sinulle.
Mene sinne, missä yleisösi jo puhuu
Kerro todellisesta yleisötutkimuksesta menemällä sinne, missä yleisösi puhuu avoimesti ja rehellisesti. Reddit-ketjut, niche-foorumit, LinkedIn-kommentit, Slack-yhteisöt ja arvostelusivustot, kuten G2 ja Trustpilot, ovat paikkoja, joissa ihmiset kysyvät suodattamattomia kysymyksiä omin sanoin. Se on juuri sellainen luonnollinen kieli, joka kuvaa tarkasti sitä, kuinka joku kehottaisi tekoälytyökalua. Jos ICP kysyy toistuvasti "miten perustelen X:n sijoitetun pääoman tuottoprosenttia CFO:lleni" subredditissä, se on paljon luotettavampi sisältötiedote kuin toimittajan kuroimaan kyselyyn liitetty volyyminumero.
Louhi omia asiakaskeskustelujasi
Asiakaskeskeiset tiimit ovat yksi eniten käytettyjä GEO-tiedon lähteitä. Myyntipuhelutallenteet, tukiliput, asiakashaastattelut ja perehdytyskeskustelut sisältävät runsaasti täsmällisiä lauseita, joita todelliset ostajat käyttävät, kun he ovat jumissa, skeptisiä tai arvioivat vaihtoehtoja. Tämä kieli kuuluu sisältöösi ja viime kädessä tekoälyvastauksiin. Jos myyntitiimisi kuulee saman vastalauseen joka viikko, on hyvä mahdollisuus, että joku kysyy tekoälyltä saman kysymyksen.
Ryhmittele ja järjestä kehotteet yleisösi kielen ympärille
Kun olet saanut raakaa tietoa ICP-työstäsi, foorumeilta ja asiakaskeskusteluistasi, seuraava vaihe on sen jäsentäminen. Sen sijaan, että käsittelisit jokaista mahdollista kehotusta erillisenä kohteena, ryhmittele ne tarkoituksen ja teeman mukaan.
Nopea ryhmitteleminen samankaltaisten aiheiden tai kipukohtien ympärille auttaa sinua näkemään malleja siinä, miten yleisösi ajattelee ongelmaa, ei vain sitä, miten he ilmaisevat yksittäisen kysymyksen. Klusteri "miten mitata GEO:n menestystä" voi sisältää kehotteita mittareista, raportoinnista, sidosryhmien kommunikaatiosta ja benchmarkingista. Jokainen niistä ansaitsee sisällön, ja niiden välinen päällekkäisyys kertoo sinulle, mikä sinun ydinkertomuksesi tulisi olla.
Tämä on merkityksellinen muutosavainsanatutkimuksen logiikka. Kun ajattelet GEO:ta vs. AEO:ta, järjestelyperiaate pysyy samana: ajankohtaista auktoriteettia yleisösi ratkaisemien ongelmien ympärillä. Nopea organisointi tarkoituksen ja teeman mukaan antaa sinun rakentaa tätä auktoriteettia järjestelmällisesti.
Käytä kehotteita äänenvoimakkuuden työkaluilla siihen, missä he todella ovat hyviä
Tämä ei tarkoita Profoundin tai Writesonicin kaltaisten alustojen hylkäämistä kokonaan. Oikein käytettynä ne ovat todella hyödyllisiä suuntatietoisuuden lisäämisessä: aiheen aukkojen havaitsemisessa, brändisi esiintymisen oikeissa keskusteluissa ja kilpailijoiden ääniosuuden seuraamisessa ajan mittaan.
lähde
Virhe on käyttää niitä avainsanojen määrän korvikkeena ja antaa niiden arvioiden ohjata luomiasi. Anna ICP:si, yleisötutkimuksesi ja todelliset asiakaskeskustelut kertoa sinulle, mitä varten sinun kannattaa optimoida. Käytä sitten nopeita tilavuustietoja painetestaukseen ja valvontaan, älä päättämiseen.
Luo tarkkailuaikataulu, joka todella toimii
Ottaen huomioon, kuinka paljon viittauksia esiintyy tekoälytuloksissa, seurannan on oltava jäsenneltyä ja johdonmukaista reaktiivisen sijaan. Brändin tekoälyn näkyvyyden tarkistaminen neljännesvuosittain ei riitä. Kuukausittainen seuranta-aikataulu ydinkehoteklustereita varten antaa sinulle kohtuullisen lähtökohdan merkityksellisten muutosten havaitsemiseen ilman yli-indeksointia melussa.
Näin lähestyt sitä käytännössä. Luo määritelty luettelo 20–30 kehotuksesta, jotka kuvastavat ICP:si yleisimpiä kysymyksiä. Suorita niitä tietyllä tahdilla, vähintään kuukausittain, yleisösi eniten käyttämillä alustoilla, kuten ChatGPT, Perplexity ja Google AI Overviews. Seuraa, näkyvätkö brändisi, sisältösi tai kilpailijasi. Huomaa muutokset, mutta älä ylireagoi yhden kuukauden vaihteluihin, koska vaihtelua on olemassa. Tarkastelet suuntaavia trendejä kolmen tai kuuden kuukauden ajalta, et viikoittain.
Tämä erottaa tiimit, joilla on todellinen tekoälyhaun optimointistrategia, niistä, jotka reagoivat kojelaudan hälytyksiin. Valvonta tiedottaa; se ei ratkaise.
Bottom Line
Kehotteen äänenvoimakkuus yrittää likimääräistä kysyntää, johon sinulla saattaa jo olla suora pääsy. Tekoälyhaussa voittaneet tuotemerkit eivät ole niitä, jotka jahtaavat eniten seurattuja kehotteita. He ymmärtävät yleisönsä riittävän syvästi näkyäkseen vastauksissa, joita heidän asiakkaat todella etsivät.
