רוב העצות לגבי שיטות עבודה מומלצות לאופטימיזציה של מנוע גנרטיבי מתחילות באותו מקום: מצא את ההנחיות שאנשים משתמשים בהן עם כלי בינה מלאכותית, עקוב אחר אילו מהן מעניקות נראות למותג שלך, ובנה תוכן סביב השאילתות בנפח הגבוה ביותר.
הבעיה? הנתונים הללו מוערכים במידה רבה.
אופטימיזציה של מנוע גנרטיבי (GEO) עדיין חדש מספיק כדי שהתשתית למדידה מדויקת עדיין לא קיימת. חשבו על הבדל GEO מ-SEO: האותות הבוגרים והאמינים שציפיתם להם מכלים כמו Semrush או Ahrefs לקח שנים לפתח. מדידת GEO עדיין לא שם. מה שפלטפורמות מכנות "נפח מהיר" מעוצב, מוערך ולעיתים שגוי בכיוון.
פוסט זה מפרק מדוע עוצמת קול מיידית היא בסיס לא אמין לאסטרטגיית ה-GEO שלך ומה הצוותים עם הביצועים הטובים ביותר עושים במקום זאת.
טייק אווי מפתח
"נפח בקשה" הוא אומדן מדגם, לא נתוני משתמש בפועל, מה שהופך אותו לנקודת התחלה לא אמינה להחלטות GEO.
התנהגות AI אינה עקבית; אנשים מנסחים הנחיות בצורה שונה ומודלים מחזירים תשובות מגוונות, מה שהופך את הדפוסים שקשה לסמוך עליהם בקנה מידה קטן.
"דירוגי" הבינה המלאכותית אינם יציבים; מחקרים מראים שהתוצאות משתנות ללא הרף, כך שמעקב אחר מיקום הדרך בה אתה עוקב אחר קידום אתרים אינו מתורגם.
רוב מקורות הנתונים, בין אם לוחות או ממשקי API, מוטים או אינם משקפים התנהגות משתמש אמיתית בכלי AI.
סחף הציטוטים גבוה, כלומר המקורות והנראות משתנים מחודש לחודש אפילו עבור הנחיות זהות.
כלי GEO הם עדיין מוקדמים ומכוונים, לא סופיים; להתייחס אליהם בהתאם.
קיבוץ הודעות סביב השפה האמיתית של ה-ICP שלך מתעלה על ביצועי המרדף אחרי רשימות שאילתות שנקבעו על ידי הספקים.
לוח זמנים עקבי של ניטור חשוב יותר מאשר אובססיביות לגבי כל נקודת נתונים בודדת.
מדוע נפח הנחיה מטעה את אסטרטגיית ה-GEO שלך
1. ל-LLMs אין נפח חיפוש: זה משוער, לא נמדד
הבעיה הבסיסית ביותר היא שאין "נפח חיפוש AI" אמיתי באופן שבו גוגל חושפת נתוני שאילתות חיפוש. LLMs אינם מפרסמים תדירות שאילתות או מקבילות לנפח חיפוש. התגובות שלהם משתנות, לפעמים בעדינות ולפעמים באופן דרמטי, אפילו עבור שאילתות זהות, עקב פענוח הסתברותי והקשר מהיר. הם תלויים גם בתכונות הקשריות נסתרות כמו היסטוריית משתמשים, מצב הפעלה והטמעות אטומות לצופים חיצוניים. מה שפלטפורמות מוכרות כ"נפח מהיר" היא אומדן מדגם, לא מדידה ישירה.
2. תגובות LLM אינן דטרמיניסטיות מטבען
נפח מילות מפתח מסורתי עובד מכיוון שמיליוני אנשים מקלידים את אותו ביטוי בגוגל והשאילתות הללו מתועדות. אינטראקציות AI שונות מהותית. התנהגות החיפוש ב-SEO מסורתי חוזרת על עצמה, עם מיליוני ביטויים זהים שמניבים מדדי נפח יציבים. אינטראקציות LLM הן דיבוריות ומשתנות. אנשים מנסחים מחדש שאלות בצורה שונה, לעתים קרובות בתוך הפעלה בודדת, מה שמקשה על זיהוי הדפוסים עם מערכי נתונים קטנים.
האי-דטרמיניזם הזה מובנה באופן שבו פועלים לימודי LLM. הם מייצרים טקסט תוך שימוש בשיטות הסתברותיות, בוחרים מילים על סמך הסבירות שלהן במקום לפי דפוס מוגדר. אותה הנחיה יכולה לייצר תגובות שונות, מה שמקשה על הסקת מסקנות עקביות ומדויקות.
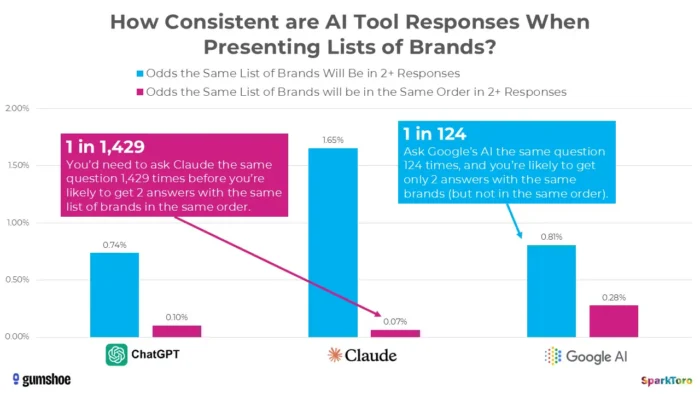
3. המחקר של SparkToro מראה שהדירוגים הם אקראיים בעיקרם
העדויות המשכנעות ביותר מגיעות ממחקר ציון דרך בינואר 2026 של רנד פישקין ו-Gumshoe.ai. הם בדקו 2,961 הנחיות על פני 600 מתנדבים ב-ChatGPT, קלוד ו-Google AI. הממצא: יש סיכוי של פחות מ-1 ל-100 לקבל את אותה רשימת מותגים בכל שתי תגובות, ופחות מ-1 ל-1,000 סיכוי לאותה רשימה באותו סדר. כפי שפישקין סיכם בבוטות, כל כלי שנותן "מיקום דירוג בבינה מלאכותית" מרכיב אותו בעצם.
מקור
מחקר מ-SparkToro מדגיש שונות משמעותית בהמלצות מותג שנוצרו בינה מלאכותית גם כאשר נעשה שימוש בהנחיות זהות, מה שמצביע על כך שמדידות נראות בינה מלאכותית בנקודת זמן עשויות לשקף תנודתיות ולא אותות ביצועים עמידים.
4. למתודולוגיה מבוססת פאנל יש בעיות הטיה מובנות
פלטפורמות כמו Profound מסתמכות על פאנלים של צרכנים בעלי הסכמה למקור הנתונים המיידיים שלהם. מעניק רישיונות עמוקים לשיחות ממספר רב של פאנלים צרכניים עם הסכמה כפולה של משתמשי מנועי מענה אמיתיים, עם קנה מידה של מאות מיליוני הנחיות בחודש, ומחיל מודל הסתברותי מתקדם כדי להרחיב תדירות, כוונה וסנטימנט רחב יותר.אוכלוסיות.
מקור
למרות שזה נשמע חזק, אופי ההצטרפות של פאנלים אלה פירושו שהדגימה עשויה להטות למשתמשים בעלי ידע טכנולוגי ומעורבים יותר, ולא חתך מייצג של האופן שבו האוכלוסייה הכללית למעשה מניעה כלי AI.
5. שאילתות API אינן משקפות התנהגות אנושית אמיתית
כלים רבים מבצעים שאילתות במודלים של בינה מלאכותית באמצעות API כדי לדמות הנחיות של משתמשים, אבל זה מציג פער נוסף. רוב כלי המעקב של AI מסתמכים על קריאות API במקום לחקות שימוש בממשק אנושי, ומחקר מוקדם מצביע על כך שתוצאות ה-API עשויות להיות שונות מתוצאות הממשק, אם כי הגודל וההשלכות של ההבדלים הללו דורשים חקירה נוספת. האופי הממוקד ב-API של שאילתות נתונים אומר גם שהתוצאות אינן מתואמות למה שבני אדם מחפשים בפועל.
6. ציטוט סחף הוא עצום ובלתי צפוי
גם אם תתעלם מכל מה למעלה, היציבות מחודש לחודש של ציטוטי AI נמוכה להחריד. מחקר של Profound מדד סחף ציטוטים חודש על פני חודש וצפה בשינויים גדולים מאוד בתחומים המצוטטים אפילו עבור הנחיות זהות. Google AI Overviews ו-ChatGPT הראו וריאציות חודשיות של עשרות נקודות אחוז.
מקור
המשמעות היא שה"נפח" המצורף לכל הנחיה נתונה היום עשוי להיראות אחרת לגמרי בחודש הבא, מה שהופך אותו לבסיס לא אמין להחלטות השקעה בתוכן.
7. אנחנו בעידן טרום סמרוש: לכלים אין עדיין תשתית
אנחנו עדיין בעידן טרום סמרוש/מוז/אהרף ללימודי תואר שני. לאף אחד אין חשיפה מלאה להשפעה של LLM על העסק שלו היום. היזהרו מכל ספק או יועץ שמבטיח נראות מלאה, כי זה פשוט לא אפשרי עדיין. יש להתייחס לנתוני המעקב הנוכחיים ככיווניים ושימושיים להחלטות, אך לא סופיות.
שיטות עבודה מומלצות לאופטימיזציה של מנועים גנרטיביים: מה לעשות במקום זאת
עוצמת קול מהירה היא אות אחד מני רבים, וכרגע זה אחד החלשים. להלן שיטות העבודה המומלצות לאופטימיזציה של מנוע יצירתי שדווקא מחזיקות מעמד.
התחל עם ה-ICP שלך, לא לוח מחוונים
במקום לתת לנפח המיידי המשוער להכתיב את סדר העדיפויות של תוכן ה-GEO שלך, התחל עם מה שאתה באמת יודע על הקהל שלך. האות החזק ביותר שיש לך הוא פרופיל הלקוח האידיאלי שלך. אילו בעיות הלקוחות הטובים ביותר שלך שוכרים אותך לפתור? באיזו שפה הם משתמשים כדי לתאר את הבעיות הללו? נקודות הכאב הללו, לא הערכות מיידיות של ספק, צריכות להיות הבסיס למה שאתה מייעל עבור תשובות בינה מלאכותית.
מקור: The Smarketers
אם ביצעת עבודת ICP מוצקה, אתה כבר יושב על נתונים טובים יותר מכל כלי נפח מהיר שיכול לתת לך.
לך לאן שהקהל שלך כבר מדבר
שלב במחקר קהל אמיתי על ידי יציאה למקום שבו הקהל שלך מדבר בפתיחות ובכנות. שרשורי Reddit, פורומי נישה, תגובות בלינקדאין, קהילות Slack ואתרי ביקורות כמו G2 ו-Truppi הם מקומות שבהם אנשים שואלים שאלות לא מסוננות במילים שלהם. זה בדיוק סוג השפה הטבעית שמתאפיין מקרוב לאופן שבו מישהו יבקש כלי בינה מלאכותית. אם ה-ICP שלך שואל שוב ושוב "איך אני מצדיק את החזר ה-ROI של X למנהל הכספים שלי" ב-subreddit, זה תקציר תוכן אמין הרבה יותר ממספר אמצעי אחסון מהיר המצורף לשאילתה שנקבעה על ידי הספק.
שליחת שיחות עם לקוחות משלך
צוותים מול לקוחות הם אחד המקורות הכי פחות בשימוש של מודיעין GEO. הקלטות שיחות מכירה, כרטיסי תמיכה, ראיונות לקוחות ושיחות הצטרפות עשירות בניסוח המדויק שהקונים האמיתיים משתמשים בהם כשהם תקועים, סקפטיים או מעריכים אפשרויות. השפה הזו שייכת לתוכן שלך ובסופו של דבר לתשובות בינה מלאכותית. אם צוות המכירות שלך שומע את אותה התנגדות מדי שבוע, יש סיכוי טוב שמישהו שואל בינה מלאכותית את אותה שאלה.
רכז וארגן הנחיות סביב שפת הקהל שלך
ברגע שיש לך קלט גולמי מעבודת ה-ICP, הפורומים ושיחות הלקוחות שלך, השלב הבא הוא בנייתו. במקום להתייחס לכל הנחיה פוטנציאלית כמטרה מבודדת, קבץ אותן לפי כוונה ונושא.
קיבוץ מהיר סביב נושאים דומים או נקודות כאב עוזרים לך לראות דפוסים של האופן שבו הקהל שלך חושב על בעיה, לא רק איך הם מנסחים שאלה בודדת. אשכול סביב "כיצד למדוד הצלחה GEO" עשוי לכלול הנחיות לגבי מדדים, דיווח, תקשורת עם בעלי עניין ומדידות. כל אחד מאלה ראוי לתוכן, והחפיפה ביניהם אומרת לך מה צריך להיות נרטיב הליבה שלך.
זהו מעבר משמעותי מהיגיון מחקר מילות מפתח. כשאתה חושב על GEO לעומת AEO, העיקרון המארגן נשאר זהה: סמכות אקטואלית סביב הבעיות שהקהל שלך מנסה לפתור. ארגון מהיר לפי כוונה ונושא הוא מה שמאפשר לך לבנות את הסמכות הזו באופן שיטתי.
השתמש בכלי נפח מהיר עבור מה שהם באמת טובים בו
כל זה לא אומר נטישת פלטפורמות כמו Profound או Writesonic לחלוטין. בשימוש נכון, הם באמת שימושיים למודעות לכיוון: איתור פערים בנושא, מעקב אחר המותג שלך מופיע בשיחות הנכונות ומעקב אחר נתח הקול מול מתחרים לאורך זמן.
מקור
הטעות היא להשתמש בהם כתחליף לנפח מילות מפתח ולתת להערכות שלהם להניע את מה שאתה יוצר. תן ל-ICP שלך, למחקר קהלים ולשיחות אמיתיות עם לקוחות להגיד לך למה לעשות אופטימיזציה. לאחר מכן השתמש בנתוני נפח מיידיים לבדיקת לחץ ולניטור, לא כדי להחליט.
בנו לוח זמנים לניטור שבאמת עובד
בהתחשב בכמה סחף ציטוטים קיים בתפוקות AI, הניטור צריך להיות מובנה ועקבי ולא תגובתי. בדיקת נראות ה-AI של המותג שלך פעם ברבעון אינה מספיקה. לוח זמנים לניטור חודשי עבור אשכולות הליבה שלך נותן לך קו בסיס סביר לאיתור שינויים משמעותיים ללא אינדקס יתר על רעש.
הנה איך לגשת לזה באופן מעשי. הגדר רשימה מוגדרת של 20 עד 30 הנחיות המשקפות את השאלות הנפוצות ביותר של ICP שלך. הפעל אותם בקצב קבוע, לפחות חודשי, על פני הפלטפורמות שהקהל שלך משתמש בהן הכי הרבה, כגון ChatGPT, Perplexity ו-Google AI Overviews. עקוב אחר האם המותג שלך, התוכן שלך או המתחרים שלך מופיעים. שים לב לשינויים, אך אל תגיב יתר על המידה לתנודות של חודש בודד בהתחשב בכמה וריאציות קיימת. מה שאתה צופה הוא מגמות כיווניות לאורך שלושה עד שישה חודשים, לא עמדות משבוע לשבוע.
זה מה שמפריד בין צוותים עם אסטרטגיית אופטימיזציה של AI אמיתית לאלו המגיבים להתראות לוח המחוונים. ניטור מודיע; זה לא מחליט.
השורה התחתונה
עוצמת הקול מנסה להעריך את הדרישה שאולי כבר יש לך גישה ישירה אליה. המותגים שמנצחים בחיפוש בינה מלאכותית הם לא אלו שרודפים אחרי ההנחיות שהכי עוקב אחריהם. הם אלה שמבינים את הקהל שלהם מספיק עמוק כדי להופיע בתשובות שהלקוחות שלהם באמת מחפשים.
