Většina rad ohledně osvědčených postupů generativní optimalizace motorů začíná na stejném místě: najděte výzvy, které lidé používají pomocí nástrojů AI, sledujte, které z nich zviditelňují vaši značku, a sestavujte obsah na základě dotazů s nejvyšším objemem.
Problém? Tyto údaje jsou z velké části odhadovány.
Generativní optimalizace motoru (GEO) je stále dostatečně nová, takže infrastruktura pro její přesné měření zatím neexistuje. Zamyslete se nad tím, jak se GEO liší od SEO: vyspělé a spolehlivé signály, které jste od nástrojů jako Semrush nebo Ahrefs očekávali, se vyvíjely roky. GEO měření zatím neexistuje. To, co platformy nazývají „rychlý objem“, je modelováno, odhadováno a často směrově nesprávné.
Tento příspěvek rozebírá, proč je rychlý objem nespolehlivým základem vaší strategie GEO a co místo toho dělají nejúspěšnější týmy.
Klíčové věci
„Okamžitý objem“ je modelovaný odhad, nikoli skutečná uživatelská data, což z něj činí nespolehlivý výchozí bod pro GEO rozhodnutí.
Chování AI je nekonzistentní; lidé formulují výzvy odlišně a modely vracejí různé odpovědi, takže v malém měřítku je obtížné věřit vzorům.
AI „žebříčky“ jsou nestabilní; studie ukazují, že se výsledky neustále mění, takže sledování pozice způsobem, jakým sledujete SEO, se nepřekládá.
Většina zdrojů dat, ať už jde o panely nebo rozhraní API, je neobjektivní nebo neodráží skutečné chování uživatelů v nástrojích AI.
Citační drift je vysoký, což znamená, že zdroje a viditelnost se mění z měsíce na měsíc, a to i u stejných výzev.
GEO nástroje jsou stále rané a směrové, ne definitivní; podle toho s nimi zacházet.
Seskupování výzev kolem skutečného jazyka vašeho ICP předčí hledání seznamů dotazů spravovaných dodavateli.
Důsledný plán monitorování je důležitější než posedlost jakýmkoliv datovým bodem.
Proč Prompt Volume zavádí vaši GEO strategii
1. LLM nemají objem vyhledávání: je odhadovaný, neměřený
Nejzásadnějším problémem je, že neexistuje žádný skutečný „objem vyhledávání AI“, jakým Google vystavuje data vyhledávacích dotazů. LLM nezveřejňují ekvivalenty frekvence dotazů ani objemu vyhledávání. Jejich odpovědi se liší, někdy jemně a někdy dramaticky, dokonce i na stejné dotazy, kvůli pravděpodobnostnímu dekódování a rychlému kontextu. Závisí také na skrytých kontextových funkcích, jako je historie uživatele, stav relace a vložení, které jsou pro externí pozorovatele neprůhledné. To, co platformy prodávají jako „rychlý objem“, je modelovaný odhad, nikoli přímé měření.
2. Odpovědi LLM jsou ze své podstaty nedeterministické
Tradiční objem klíčových slov funguje, protože miliony lidí zadávají stejnou frázi do Googlu a tyto dotazy se zaznamenávají. Interakce AI se zásadně liší. Chování při vyhledávání v tradičním SEO se opakuje a miliony stejných frází zajišťují stabilní metriky objemu. Interakce LLM jsou konverzační a variabilní. Lidé přeformulují otázky odlišně, často během jediné relace, což ztěžuje rozpoznávání vzorů u malých souborů dat.
Tento nedeterminismus je zapékán do toho, jak LLM fungují. Vytvářejí text pomocí pravděpodobnostních metod, vybírají slova na základě jejich pravděpodobnosti spíše než podle stanoveného vzoru. Stejná výzva může vyvolat různé reakce, což ztěžuje vyvozování konzistentních a přesných závěrů.
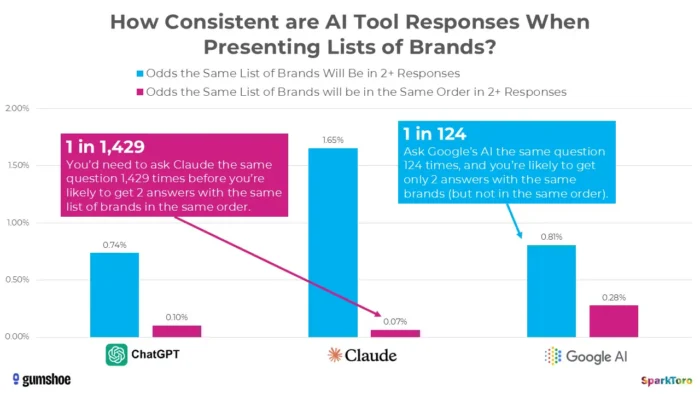
3. Výzkum SparkToro ukazuje, že hodnocení jsou v podstatě náhodná
Nejpřesvědčivější důkazy pochází z přelomové studie z ledna 2026, kterou provedli Rand Fishkin a Gumshoe.ai. Testovali 2 961 výzev u 600 dobrovolníků na ChatGPT, Claude a Google AI. Zjištění: šance na získání stejného seznamu značek v libovolných dvou odpovědích je menší než jedna ku 100 a šance na stejný seznam ve stejném pořadí menší než jedna ku 1000. Jak Fishkin bez obalu uzavřel, jakýkoli nástroj, který poskytuje „umístění v žebříčku v AI“, je v podstatě tvoří.
Zdroj
Výzkum společnosti SparkToro zdůrazňuje významnou variabilitu doporučení značky generovaných umělou inteligencí, i když jsou použity stejné výzvy, což naznačuje, že měření viditelnosti AI v určitém okamžiku mohou odrážet volatilitu spíše než trvalé signály výkonu.
4. Panelová metodologie má přirozené problémy se zkreslením
Platformy jako Profound se při získávání rychlých dat spoléhají na opt-in spotřebitelské panely. Společnost Profound licencuje konverzace z několika spotřebitelských panelů skutečných uživatelů odpovědí s dvojitým přihlášením, s rozsahem ve stovkách milionů výzev za měsíc, a aplikuje pokročilé pravděpodobnostní modelování k extrapolaci frekvence, záměru a sentimentu v širším měřítku.populace.
Zdroj
I když to zní robustně, povaha těchto panelů s možností přihlášení znamená, že vzorek se může vychýlit směrem k technicky zdatnějším a zaujatějším uživatelům, nikoli k reprezentativnímu průřezu toho, jak obecná populace skutečně vybízí nástroje umělé inteligence.
5. Dotazy API neodrážejí skutečné lidské chování
Mnoho nástrojů se dotazuje na modely umělé inteligence prostřednictvím rozhraní API, aby simulovaly uživatelské výzvy, ale to přináší další mezeru. Většina nástrojů pro sledování AI se spoléhá spíše na volání API než na napodobování lidského rozhraní a raný výzkum naznačuje, že výsledky API se mohou lišit od výsledků rozhraní, i když velikost a důsledky těchto rozdílů vyžadují další zkoumání. Povaha dotazování na data zaměřená na API také znamená, že výsledky nejsou v souladu s tím, co lidé skutečně hledají.
6. Citační posun je masivní a nepředvídatelný
I když ignorujete vše výše uvedené, meziměsíční stabilita citací AI je šokující nízká. Studie společnosti Profound měřila posun citací z měsíce na měsíc a pozorovala velmi velké změny v citovaných doménách i u stejných výzev. Přehledy Google AI a ChatGPT vykazovaly měsíční variace v desítkách procentních bodů.
Zdroj
To znamená, že „svazek“ připojený k jakékoli dané výzvě dnes může příští měsíc vypadat úplně jinak, což z něj činí nespolehlivý základ pro rozhodování o investicích do obsahu.
7. Nacházíme se v éře před Semrush: Nástroje ještě nemají infrastrukturu
Pro LLM jsme stále v éře před Semrush/Moz/Ahrefs. Nikdo dnes nemá úplný přehled o dopadu LLM na své podnikání. Dejte si pozor na jakéhokoli dodavatele nebo konzultanta, který slibuje úplnou viditelnost, protože to prostě zatím není možné. Aktuální sledovací data by měla být považována za směrová a užitečná pro rozhodování, ale ne za definitivní.
Doporučené postupy pro generativní optimalizaci motoru: Co dělat místo toho
Okamžitá hlasitost je jedním z mnoha signálů a právě teď je to jeden z těch slabších. Zde jsou osvědčené postupy pro generativní optimalizaci motorů, které skutečně obstojí.
Začněte se svým ICP, ne s řídicím panelem
Spíše než nechat odhadovaný okamžitý objem určovat vaše priority obsahu GEO, začněte tím, co o svém publiku skutečně víte. Nejsilnějším signálem, který máte, je váš profil ideálního zákazníka. Jaké problémy si vaši nejlepší zákazníci najímají na řešení? Jaký jazyk používají k popisu těchto problémů? Tyto bolestivé body, nikoli rychlé odhady modelované dodavatelem, by měly být základem toho, pro co optimalizujete v odpovědích AI.
Zdroj: The Smarketers
Pokud jste odvedli solidní práci s ICP, už sedíte na lepších datech, než vám může poskytnout jakýkoli nástroj pro rychlé objemy.
Jděte tam, kde už vaše publikum mluví
Navrstvěte skutečný průzkum publika tím, že půjdete tam, kde vaše publikum mluví otevřeně a upřímně. Vlákna na Redditu, specializovaná fóra, komentáře na LinkedIn, komunity Slack a recenzní weby jako G2 a Trustpilot jsou místa, kde lidé pokládají nefiltrované otázky svými vlastními slovy. To je přesně ten druh přirozeného jazyka, který se blíží tomu, jak by někdo vyvolal nástroj AI. Pokud se váš ICP opakovaně ptá „jak zdůvodním ROI X svému finančnímu řediteli“ na subredditu, je to mnohem spolehlivější obsah než rychlé číslo svazku připojené k dotazu vedeném dodavatelem.
Vytěžujte své vlastní zákaznické konverzace
Týmy zaměřené na zákazníky jsou jedním z nejvíce málo využívaných zdrojů GEO inteligence. Nahrávky prodejních hovorů, lístky na podporu, rozhovory se zákazníky a vstupní rozhovory jsou bohaté na přesné fráze, které skuteční kupující používají, když jsou zaseklí, skeptičtí nebo hodnotí možnosti. Tento jazyk patří do vašeho obsahu a nakonec do odpovědí AI. Pokud váš prodejní tým slyší každý týden stejnou námitku, je velká šance, že někdo položí AI stejnou otázku.
Seskupte a uspořádejte výzvy podle jazyka vašeho publika
Jakmile budete mít hrubý vstup ze své práce ICP, fór a konverzací se zákazníky, dalším krokem je jeho strukturování. Spíše než považovat každou potenciální výzvu za izolovaný cíl, seskupte je podle záměru a tématu.
Pohotové seskupení kolem podobných témat nebo bolestivých bodů vám pomůže vidět vzorce v tom, jak vaše publikum přemýšlí o problému, nejen jak formuluje jednu otázku. Seskupení kolem „jak měřit úspěšnost GEO“ může zahrnovat výzvy k metrikám, reportingu, komunikaci se zúčastněnými stranami a benchmarkingu. Každý z nich si zaslouží obsah a jejich překrývání vám říká, jaký by měl být váš hlavní příběh.
Toto je smysluplný posun odlogika výzkumu klíčových slov. Když přemýšlíte o GEO versus AEO, princip organizace zůstává stejný: aktuální autorita kolem problémů, které se vaše publikum snaží vyřešit. Pohotová organizace podle záměru a tématu je to, co vám umožní systematicky budovat tuto autoritu.
Použijte nástroje Prompt Volume k tomu, v čem jsou skutečně dobří
Nic z toho neznamená úplně opustit platformy jako Profound nebo Writesonic. Jsou-li správně používány, jsou skutečně užitečné pro orientaci: odhalování mezer v tématu, sledování, zda se vaše značka objevuje ve správných konverzacích, a sledování podílu hlasu oproti konkurentům v průběhu času.
Zdroj
Chybou je používat je jako náhradu objemu klíčových slov a nechat jejich odhady řídit to, co vytvoříte. Nechte své ICP, průzkum publika a skutečné konverzace se zákazníky, aby vám řekly, pro co optimalizovat. Poté použijte okamžitá objemová data k tlakové zkoušce a monitorování, nikoli k rozhodování.
Sestavte si plán monitorování, který skutečně funguje
Vzhledem k tomu, jak velký citační posun ve výstupech AI existuje, musí být monitorování strukturované a konzistentní, nikoli reaktivní. Kontrola viditelnosti AI vaší značky jednou za čtvrtletí nestačí. Měsíční plán monitorování pro vaše základní klastrové výzvy vám poskytuje rozumný základ pro zjištění smysluplných směn bez nadměrného indexování hluku.
Zde je návod, jak k tomu přistupovat prakticky. Vytvořte definovaný seznam 20 až 30 výzev, které odrážejí nejčastější otázky vašeho ICP. Spouštějte je v nastavené kadenci, alespoň měsíčně, na platformách, které vaše publikum nejčastěji používá, jako jsou ChatGPT, Perplexity a Google AI Overviews. Sledujte, zda se zobrazuje vaše značka, váš obsah nebo vaši konkurenti. Všimněte si změn, ale nereagujte přehnaně na výkyvy za jeden měsíc vzhledem k tomu, jak velké rozdíly existují. To, co sledujete, jsou směrové trendy za tři až šest měsíců, nikoli pozice z týdne na týden.
To je to, co odděluje týmy se skutečnou strategií optimalizace vyhledávání AI od těch, kteří reagují na upozornění na řídicím panelu. Monitoring informuje; to nerozhoduje.
Sečteno a podtrženo
Prompt volume se snaží přiblížit poptávce, ke které již můžete mít přímý přístup. Značky, které vyhrávají ve vyhledávání AI, nejsou ty, které sledují ty nejsledovanější výzvy. Jsou to oni, kdo chápou své publikum dostatečně hluboce na to, aby se ukázalo v odpovědích, které jejich zákazníci skutečně hledají.
