關於生成引擎優化最佳實踐的大多數建議都是從同一個地方開始的:找到人們使用人工智慧工具的提示,追蹤哪些提示可以為您的品牌帶來知名度,並圍繞最高量的查詢建立內容。
問題?該數據很大程度上是估計的。
生成式引擎優化(GEO)仍然很新,以至於準確測量它的基礎設施還不存在。想想 GEO 與 SEO 有何不同:您所期望的 Semrush 或 Ahrefs 等工具所提供的成熟、可靠的訊號需要數年時間才能開發出來。 GEO 測量尚未實現。平台所謂的「即時成交量」是經過建模和估計的,而且往往方向錯誤。
這篇文章詳細分析了為什麼即時成交量對於 GEO 策略來說是不可靠的基礎,以及表現最好的團隊會做什麼。
重點
「提示量」是一個模型估計,而不是實際的使用者數據,這使得它成為 GEO 決策的不可靠起點。
AI行為不一致;人們給出不同的措詞提示,模型回傳不同的答案,使得小規模的模式難以信任。
AI「排名」不穩定;研究顯示結果不斷變化,因此追蹤 SEO 的方式無法轉化為追蹤位置。
大多數資料來源,無論是面板還是 API,都是有偏見的,或者不能反映人工智慧工具中的真實使用者行為。
引用漂移很高,這意味著即使對於相同的提示,來源和可見度也會逐月變化。
GEO 工具仍處於早期階段,具有方向性,並非確定性的;相應地對待他們。
圍繞 ICP 的實際語言進行聚類提示優於追逐供應商策劃的查詢清單。
一致的監控計劃比沉迷於任何單一數據點更重要。
為什麼提示交易量會誤導您的 GEO 策略
1. 法學碩士沒有搜尋量:它是估計的,而不是測量的
最根本的問題是,Google公開搜尋查詢資料的方式並不存在真正的「人工智慧搜尋量」。法學碩士不會發布查詢頻率或搜尋量等值。由於機率解碼和提示上下文,即使對於相同的查詢,他們的反應也會有所不同,有時是微妙的,有時是巨大的。它們還依賴隱藏的上下文功能,例如使用者歷史記錄、會話狀態和對外部觀察者不透明的嵌入。平台銷售的「即時成交量」是模型估算,而不是直接測量。
2. LLM 的回答本質上是非確定性的
傳統的關鍵字量之所以有效,是因為數百萬人在Google中輸入相同的短語,而這些查詢被記錄下來。人工智慧互動有著根本的不同。傳統 SEO 中的搜尋行為是重複的,數以百萬計的相同短語驅動著穩定的流量指標。 LLM 的互動是對話式的、多變的。人們通常會在一次會話中以不同的方式重新表達問題,這使得小資料集的模式識別變得更加困難。
這種不確定性已經融入法學碩士的工作方式中。他們使用機率方法產生文本,根據單字的可能性而不是遵循設定的模式來選擇單字。相同的提示可能會產生不同的反應,這使得很難得出一致且準確的結論。
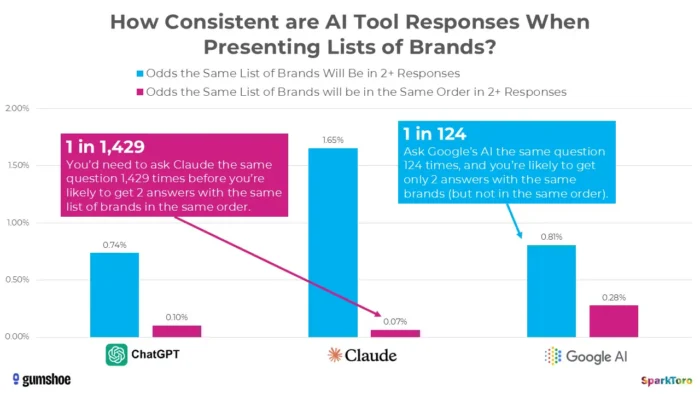
3. SparkToro 的研究顯示排名本質上是隨機的
最令人信服的證據來自 Rand Fishkin 和 Gumshoe.ai 於 2026 年 1 月進行的一項具有里程碑意義的研究。他們在 ChatGPT、Claude 和 Google AI 上測試了 600 名志願者的 2,961 個提示。研究結果:在任兩個回應中獲得相同品牌清單的幾率不到百分之一,以相同順序獲得相同清單的幾率不到千分之一。正如菲甚金直言不諱的結論,任何給出「人工智慧排名」的工具本質上都是編造的。
來源
SparkToro 的研究強調,即使使用相同的提示,人工智慧產生的品牌推薦也會存在顯著差異,這表明人工智慧可見性的時間點測量可能反映的是波動性,而不是持久的績效訊號。
4. 基於小組的方法存在固有的偏差問題
像 Profound 這樣的平台依靠選擇加入的消費者群組來獲取即時數據。 Profound 授權來自真實答案引擎使用者的多個雙重選擇加入消費者群組的對話,每月有數億個提示,並應用先進的機率模型來推斷更廣泛的頻率、意圖和情緒人口。
來源
雖然這聽起來很可靠,但這些小組的選擇加入性質意味著樣本可能會偏向於更精通技術、更積極參與的用戶,而不是一般人群實際如何提示人工智慧工具的代表性橫截面。
5. API 查詢不能反映真實的人類行為
許多工具透過 API 查詢 AI 模型來模擬使用者提示,但這又帶來了另一個差距。大多數人工智慧追蹤工具依賴 API 調用,而不是模仿人機介面的使用,早期研究表明 API 結果可能與介面結果不同,儘管這些差異的程度和影響需要進一步調查。查詢資料以 API 為中心的本質也意味著結果與人類實際搜尋的內容不一致。
6. 引文漂移巨大且不可預測
即使你忽略以上所有內容,人工智慧引用的月度穩定性也低得驚人。 Profound 的一項研究逐月測量了引文漂移,並觀察到即使對於相同的提示,被引領域也存在很大的變化。 Google AI Overviews 和 ChatGPT 顯示每月有數十個百分點的變化。
來源
這意味著今天任何給定提示所附加的「數量」可能在下個月看起來完全不同,使其成為內容投資決策的不可靠基礎。
7. 我們正處於 Semrush 之前的時代:工具尚不具備基礎設施
對於法學碩士來說,我們仍處於 Semrush/Moz/Ahrefs 之前的時代。如今,沒有人能夠完全了解法學碩士對其業務的影響。警惕任何承諾完全可見性的供應商或顧問,因為這根本不可能。目前的追蹤資料應被視為有方向性且對決策有用,但不是決定性的。
生成引擎優化最佳實務:該怎麼做
提示成交量是眾多訊號之一,但目前它是較弱的訊號之一。以下是實際有效的生成引擎優化最佳實踐。
從您的 ICP 開始,而不是儀表板
不要讓估計的提示量決定您的 GEO 內容優先級,而是從您對受眾的實際了解開始。您擁有的最強訊號是您的理想客戶檔案。您最好的客戶僱用您來解決哪些問題?他們用什麼語言來描述這些問題?這些痛點,而不是供應商建模的即時估計,應該成為您在人工智慧答案中優化的基礎。
資料來源:行銷人員
如果您已經完成了紮實的 ICP 工作,那麼您已經獲得了比任何提示量工具都能提供的更好的數據。
去你的觀眾已經談過的地方
透過深入受眾公開、誠實地發言的地方,進行真正的受眾研究。 Reddit 主題、利基論壇、LinkedIn 評論、Slack 社群以及 G2 和 Trustpilot 等評論網站是人們用自己的語言提出未經過濾的問題的地方。這正是一種自然語言,與人們如何提示人工智慧工具密切相關。如果您的 ICP 在 Reddit 子版塊中反覆詢問“我如何向 CFO 證明 X 的投資回報率”,那麼這是一個比附在供應商策劃的查詢上的提示卷號更可靠的內容簡介。
挖掘您自己的客戶對話
面向客戶的團隊是 GEO 情報最未被充分利用的來源之一。銷售電話錄音、支援票、客戶訪談和入職對話中都包含了真實買家在陷入困境、持懷疑態度或評估選項時所使用的準確措辭。該語言屬於您的內容,並最終屬於人工智慧答案。如果你的銷售團隊每週都會聽到同樣的反對意見,那麼很有可能有人向人工智慧提出同樣的問題。
圍繞受眾的語言聚集和組織提示
一旦您從 ICP 工作、論壇和客戶對話中獲得原始輸入,下一步就是建立它。不要將每個潛在的提示視為一個孤立的目標,而是按意圖和主題對它們進行分組。
圍繞相似的主題或痛點進行快速聚類可以幫助您了解受眾思考問題的模式,而不僅僅是他們如何表達單一問題。圍繞「如何衡量 GEO 成功」的集群可能包括有關指標、報告、利害關係人溝通和基準測試的提示。每一個都值得內容,它們之間的重疊告訴你你的核心敘事應該是什麼。
這是一個有意義的轉變關鍵字研究邏輯。當您考慮 GEO 與 AEO 時,組織原則保持不變:圍繞受眾試圖解決的問題的主題權威。按意圖和主題進行及時組織可以讓您有系統地建立權威。
使用提示音量工具來完成他們真正擅長的事情
這並不意味著完全放棄 Profound 或 Writesonic 等平台。如果使用得當,它們對於方向意識確實很有用:發現主題差距,監控您的品牌是否出現在正確的對話中,以及隨著時間的推移追蹤競爭對手的聲音份額。
來源
錯誤在於使用它們作為關鍵字量的替代品,並讓他們的估計驅動您創建的內容。讓您的 ICP、受眾研究和真實的客戶對話告訴您要優化什麼。然後使用即時成交量數據進行壓力測試和監控,而不是做出決定。
制定實際的監控計劃
考慮到人工智慧輸出中存在多少引文漂移,監控需要結構化且一致,而不是被動的。每季檢查一次品牌的人工智慧知名度是不夠的。核心提示群集的每月監控計畫為您提供了合理的基線,用於發現有意義的變化,而不會過度索引雜訊。
以下是實際處理方法。設定包含 20 到 30 個提示的定義列表,反映 ICP 最常見的問題。按照設定的節奏(至少每月一次)在受眾最常使用的平台上運行它們,例如 ChatGPT、Perplexity 和 Google AI Overviews。追蹤您的品牌、內容或競爭對手是否出現。注意變化,但考慮到存在多少變化,不要對單月波動反應過度。您關注的是三到六個月的方向趨勢,而不是每週的部位。
這就是擁有真正的人工智慧搜尋優化策略的團隊與對儀表板警報做出反應的團隊之間的區別。監控通知;它不能決定。
底線
提示量嘗試近似您可能已經可以直接存取的需求。在人工智慧搜尋中獲勝的品牌並不是那些追逐最多追蹤提示的品牌。他們足夠深入地了解受眾,能夠在客戶實際尋找的答案中找到答案。
