De fleste råd om bedste fremgangsmåder til generativ motoroptimering starter samme sted: find de prompter, folk bruger med AI-værktøjer, spor hvilke der giver dit brand synlighed, og opbyg indhold omkring forespørgsler med det højeste antal.
Problemet? Disse data er stort set estimerede.
Generativ motoroptimering (GEO) er stadig ny nok til, at infrastrukturen til at måle den nøjagtigt ikke eksisterer endnu. Tænk på, hvordan GEO adskiller sig fra SEO: de modne, pålidelige signaler, du er kommet til at forvente fra værktøjer som Semrush eller Ahrefs, tog år at udvikle. GEO-måling er der ikke endnu. Hvad platforme kalder "prompt volumen" er modelleret, estimeret og ofte retningsbestemt forkert.
Dette indlæg bryder ned, hvorfor promptvolumen er et upålideligt grundlag for din GEO-strategi, og hvad de bedst præsterende teams gør i stedet.
Nøgle takeaways
"Prompt volumen" er et modelleret estimat, ikke faktiske brugerdata, hvilket gør det til et upålideligt udgangspunkt for GEO-beslutninger.
AI-adfærd er inkonsekvent; folk fraser prompter forskelligt, og modeller giver forskellige svar, hvilket gør mønstre svære at stole på i lille skala.
AI "rangeringer" er ustabile; undersøgelser viser, at resultaterne ændrer sig konstant, så sporingspositionen, som du sporer SEO, oversætter ikke.
De fleste datakilder, uanset om det er paneler eller API'er, er partiske eller afspejler ikke reel brugeradfærd i AI-værktøjer.
Citationsdrift er høj, hvilket betyder, at kilder og synlighed skifter måned til måned, selv for identiske meddelelser.
GEO-værktøjer er stadig tidlige og retningsbestemte, ikke endelige; behandle dem derefter.
Klynger af prompter omkring din ICP's faktiske sprog overgår det at jagte leverandør-kuraterede forespørgselslister.
En konsekvent overvågningsplan betyder mere end at besætte et enkelt datapunkt.
Hvorfor prompt volumen vildleder din GEO-strategi
1. LLM'er har ikke søgevolumen: Det er estimeret, ikke målt
Det mest fundamentale problem er, at der ikke er nogen ægte "AI-søgevolumen", som Google eksponerer søgeforespørgselsdata på. LLM'er udgiver ikke forespørgselsfrekvens eller tilsvarende søgevolumen. Deres svar varierer, nogle gange subtilt og nogle gange dramatisk, selv for identiske forespørgsler, på grund af probabilistisk afkodning og hurtig kontekst. De afhænger også af skjulte kontekstuelle funktioner som brugerhistorie, sessionstilstand og indlejringer, der er uigennemsigtige for eksterne observatører. Hvad platforme sælger som "prompt volumen" er et modelleret estimat, ikke en direkte måling.
2. LLM-svar er ikke-deterministiske af natur
Traditionel søgeordsvolumen virker, fordi millioner af mennesker skriver den samme sætning i Google, og disse forespørgsler logges. AI-interaktioner er fundamentalt forskellige. Søgeadfærd i traditionel SEO er gentagen, med millioner af identiske sætninger, der driver stabile volumenmålinger. LLM-interaktioner er konverserende og variable. Folk omformulerer spørgsmål forskelligt, ofte inden for en enkelt session, hvilket gør mønstergenkendelse sværere med små datasæt.
Denne ikke-determinisme er bagt ind i, hvordan LLM'er fungerer. De producerer tekst ved hjælp af probabilistiske metoder, og vælger ord baseret på deres sandsynlighed i stedet for at følge et fast mønster. Den samme prompt kan give forskellige svar, hvilket gør konsistente og nøjagtige konklusioner svære at drage.
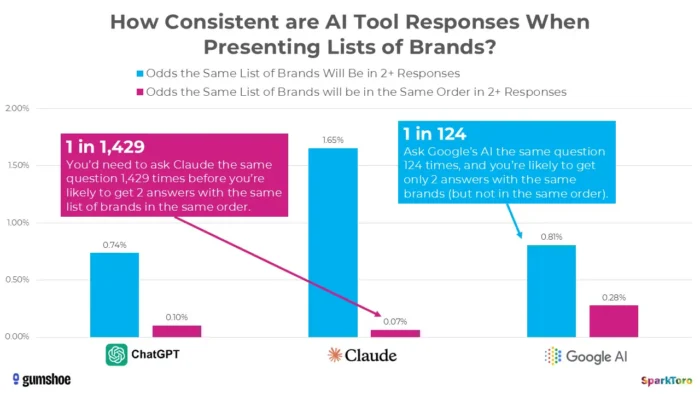
3. SparkToros forskning viser, at rangeringer i det væsentlige er tilfældige
Det mest overbevisende bevis kommer fra en skelsættende undersøgelse fra januar 2026 af Rand Fishkin og Gumshoe.ai. De testede 2.961 prompter på tværs af 600 frivillige på ChatGPT, Claude og Google AI. Konstateringen: Der er mindre end én ud af 100 chance for at få den samme mærkeliste i to svar, og mindre end én ud af 1.000 chance for den samme liste i samme rækkefølge. Som Fishkin ligeud konkluderede, er ethvert værktøj, der giver en "rangeringsposition i AI", i det væsentlige det op.
Kilde
Forskning fra SparkToro fremhæver betydelig variabilitet i AI-genererede mærkeanbefalinger, selv når identiske prompter bruges, hvilket tyder på, at point-in-time AI-synlighedsmålinger kan afspejle volatilitet snarere end holdbare ydeevnesignaler.
4. Panel-baseret metodologi har iboende bias-problemer
Platforme som Profound er afhængige af opt-in forbrugerpaneler til at hente deres hurtige data. Dybdegående licenserer samtaler fra flere, dobbelt tilvalgte forbrugerpaneler af brugere af rigtige svarmotorer, med en skala i hundreder af millioner af forespørgsler om måneden, og anvender avanceret probabilistisk modellering til at ekstrapolere frekvens, hensigt og følelser på tværs af brederebefolkninger.
Kilde
Selvom dette lyder robust, betyder opt-in-karakteren af disse paneler, at prøven kan vende sig mod mere teknologikyndige, engagerede brugere, ikke et repræsentativt tværsnit af, hvordan den generelle befolkning faktisk anmoder om AI-værktøjer.
5. API-forespørgsler afspejler ikke ægte menneskelig adfærd
Mange værktøjer forespørger AI-modeller via API for at simulere brugermeddelelser, men dette introducerer endnu et hul. De fleste AI-sporingsværktøjer er afhængige af API-kald frem for at efterligne brugen af menneskelig grænseflade, og tidlig forskning tyder på, at API-resultater kan afvige fra grænsefladeresultater, selvom størrelsen og implikationerne af disse forskelle kræver yderligere undersøgelse. Den API-fokuserede karakter af forespørgsler på data betyder også, at resultaterne ikke stemmer overens med det, mennesker rent faktisk søger efter.
6. Citation Drift er massiv og uforudsigelig
Selv hvis du ignorerer alt ovenfor, er stabiliteten fra måned til måned for AI-citater chokerende lav. En undersøgelse af Profound målte citationsdrift måned over måned og observerede meget store ændringer i citerede domæner selv for identiske prompter. Google AI Overviews og ChatGPT viste månedlige variationer på snesevis af procentpoint.
Kilde
Dette betyder, at "volumen" knyttet til enhver given prompt i dag kan se helt anderledes ud i næste måned, hvilket gør det til et upålideligt grundlag for beslutninger om indholdsinvestering.
7. Vi er i en Pre-Semrush-æra: Værktøjerne har endnu ikke infrastrukturen
Vi er stadig i en præ-Semrush/Moz/Ahrefs-æra for LLM'er. Ingen har fuldstændig indsigt i LLM's indvirkning på deres virksomhed i dag. Vær på vagt over for enhver leverandør eller konsulent, der lover fuldstændig synlighed, for det er simpelthen ikke muligt endnu. Aktuelle sporingsdata bør behandles som retningsgivende og nyttige til beslutninger, men ikke endelige.
Generative Engine Optimization Best Practices: Hvad skal man gøre i stedet
Hurtig lydstyrke er ét signal blandt mange, og lige nu er det et af de svagere. Her er de bedste fremgangsmåder til generativ motoroptimering, der faktisk holder.
Start med din ICP, ikke et dashboard
I stedet for at lade estimeret promptvolumen diktere dine GEO-indholdsprioriteter, skal du starte med, hvad du faktisk ved om dit publikum. Det stærkeste signal, du har, er din ideelle kundeprofil. Hvilke problemer ansætter dine bedste kunder dig til at løse? Hvilket sprog bruger de til at beskrive disse problemer? Disse smertepunkter, ikke en leverandørs modellerede prompte estimater, bør være grundlaget for, hvad du optimerer til i AI-svar.
Kilde: The Smarketers
Hvis du har udført solidt ICP-arbejde, sidder du allerede på bedre data, end noget prompt-volumenværktøj kan give dig.
Gå, hvor dit publikum allerede taler
Læg et lag i reel publikumsforskning ved at gå, hvor dit publikum taler åbent og ærligt. Reddit-tråde, nichefora, LinkedIn-kommentarer, Slack-fællesskaber og anmeldelsessider som G2 og Trustpilot er steder, hvor folk stiller ufiltrerede spørgsmål med deres egne ord. Det er præcis den slags naturligt sprog, der knytter sig tæt til, hvordan nogen ville bede et AI-værktøj. Hvis din ICP gentagne gange spørger "hvordan retfærdiggør jeg ROI'et af X til min CFO" i en subreddit, er det en langt mere pålidelig indholdsoversigt end et prompt volumennummer knyttet til en leverandør-kurateret forespørgsel.
Mine dine egne kundesamtaler
Kundevendte teams er en af de mest underudnyttede kilder til GEO-intelligens. Optagelser af salgsopkald, supportbilletter, kundeinterviews og onboarding-samtaler er fyldt med den nøjagtige sætning, rigtige købere bruger, når de sidder fast, er skeptiske eller vurderer muligheder. Det sprog hører hjemme i dit indhold og i sidste ende i AI-svar. Hvis dit salgsteam hører den samme indvending hver uge, er der en god chance for, at nogen stiller en AI det samme spørgsmål.
Klynger og organiser meddelelser omkring dit publikums sprog
Når du har rå input fra dit ICP-arbejde, fora og kundesamtaler, er næste skridt at strukturere det. I stedet for at behandle hver potentiel prompt som et isoleret mål, grupper dem efter hensigt og tema.
Hurtig gruppering omkring lignende emner eller smertepunkter hjælper dig med at se mønstre i, hvordan dit publikum tænker på et problem, ikke kun hvordan de formulerer et enkelt spørgsmål. En klynge omkring "hvordan man måler GEO-succes" kan omfatte meddelelser om metrics, rapportering, interessentkommunikation og benchmarking. Hver af dem fortjener indhold, og overlapningen mellem dem fortæller dig, hvad din kernefortælling skal være.
Dette er et meningsfuldt skift frasøgeordsforskningslogik. Når du tænker på GEO versus AEO, forbliver organiseringsprincippet det samme: aktuel autoritet omkring de problemer, dit publikum forsøger at løse. Hurtig organisering efter hensigt og tema er det, der lader dig opbygge denne autoritet systematisk.
Brug prompt-volumenværktøjer til det, de faktisk er gode til
Intet af dette betyder helt at opgive platforme som Profound eller Writesonic. Brugt korrekt er de virkelig nyttige til retningsbestemt bevidsthed: spotte emnehuller, overvåge, om dit brand optræder i de rigtige samtaler, og sporing af stemmeandel over tid over tid.
Kilde
Fejlen er at bruge dem som en erstatning for søgeordsvolumen og lade deres estimater drive det, du opretter. Lad din ICP, publikumsundersøgelse og rigtige kundesamtaler fortælle dig, hvad du skal optimere til. Brug derefter prompte volumendata til at trykteste og overvåge, ikke til at bestemme.
Opbyg en overvågningsplan, der rent faktisk virker
I betragtning af hvor meget citationsdrift der findes i AI-output, skal overvågning være struktureret og konsistent snarere end reaktiv. Det er ikke nok at tjekke dit brands AI-synlighed en gang i kvartalet. En månedlig overvågningsplan for dine kernepromptklynger giver dig en rimelig baseline for at opdage meningsfulde skift uden overindeksering af støj.
Sådan griber du det praktisk an. Opret en defineret liste med 20 til 30 prompter, der afspejler din ICP's mest almindelige spørgsmål. Kør dem på en fast kadence, mindst hver måned, på tværs af de platforme, dit publikum bruger mest, såsom ChatGPT, Perplexity og Google AI Overviews. Spor om dit brand, dit indhold eller dine konkurrenter dukker op. Bemærk ændringer, men overreager ikke på enkeltmåneders udsving i betragtning af hvor meget variation der findes. Det, du holder øje med, er retningstendenser over tre til seks måneder, ikke uge-til-uge-stillinger.
Det er det, der adskiller teams med en ægte AI-søgeoptimeringsstrategi fra dem, der reagerer på dashboard-advarsler. Overvågning informerer; det bestemmer ikke.
Bundlinjen
Promptvolumen forsøger at tilnærme efterspørgsel, som du muligvis allerede har direkte adgang til. De mærker, der vinder i AI-søgning, er ikke dem, der jagter de mest sporede prompter. Det er dem, der forstår deres publikum dybt nok til at dukke op i de svar, deres kunder rent faktisk leder efter.
