بیشتر توصیههای مربوط به بهترین شیوههای بهینهسازی موتور مولد از یک جا شروع میشود: پیامهایی را که مردم با ابزارهای هوش مصنوعی استفاده میکنند، پیدا کنید، ردیابی کنید که کدام یک به برند شما قابل مشاهده است، و محتوا را با بیشترین حجم جستجوها بسازید.
مشکل؟ این داده ها تا حد زیادی تخمین زده می شود.
بهینه سازی موتور مولد (GEO) هنوز به اندازه کافی جدید است که زیرساخت اندازه گیری دقیق آن هنوز وجود ندارد. به تفاوت GEO با SEO فکر کنید: سیگنال های بالغ و قابل اعتمادی که از ابزارهایی مانند Semrush یا Ahrefs انتظار دارید، سال ها طول کشید تا توسعه یابد. اندازهگیری GEO هنوز وجود ندارد. آنچه پلتفرمها آن را «حجم سریع» مینامند، مدلسازی شده، تخمین زده میشود و اغلب از جهت اشتباه است.
این پست توضیح میدهد که چرا حجم سریع پایه غیرقابل اعتمادی برای استراتژی GEO شما است و تیمهای با بهترین عملکرد در عوض چه میکنند.
خوراکی های کلیدی
"حجم سریع" یک تخمین مدل شده است، نه داده های واقعی کاربر، که آن را به نقطه شروع غیرقابل اعتماد برای تصمیم گیری های GEO تبدیل می کند.
رفتار هوش مصنوعی ناسازگار است. عبارات افراد متفاوت است و مدل ها پاسخ های متنوعی را ارائه می دهند، که باعث می شود اعتماد به الگوها در مقیاس کوچک دشوار باشد.
"رتبه بندی" هوش مصنوعی ناپایدار است. مطالعات نشان می دهد که نتایج به طور مداوم تغییر می کنند، بنابراین ردیابی موقعیت به روشی که سئو را دنبال می کنید ترجمه نمی شود.
بیشتر منابع داده، اعم از پانل ها یا API ها، مغرضانه هستند یا رفتار واقعی کاربر را در ابزارهای هوش مصنوعی منعکس نمی کنند.
جابجایی نقل قول زیاد است، به این معنی که منابع و قابلیت مشاهده ماه به ماه حتی برای درخواستهای یکسان تغییر میکنند.
ابزارهای GEO هنوز اولیه و جهت دار هستند و قطعی نیستند. مطابق با آنها رفتار کنید.
درخواستهای خوشهبندی در اطراف زبان واقعی ICP شما از تعقیب فهرستهای پرس و جوی تنظیمشده توسط فروشنده بهتر عمل میکند.
یک برنامه نظارت ثابت بیشتر از وسواس در مورد هر نقطه داده ای منفرد اهمیت دارد.
چرا حجم سریع استراتژی GEO شما را گمراه می کند؟
1. LLM ها حجم جستجو ندارند: تخمین زده شده است، اندازه گیری نشده است
اساسیترین مشکل این است که هیچ «حجم جستجوی هوش مصنوعی» درستی وجود ندارد که Google دادههای جستجو را در معرض نمایش قرار میدهد. LLM ها فرکانس پرس و جو یا معادل حجم جستجو را منتشر نمی کنند. پاسخهای آنها به دلیل رمزگشایی احتمالی و زمینههای سریع، گاهی به صورت نامحسوس و گاهی بهطور چشمگیر، حتی برای پرسشهای یکسان، متفاوت است. آنها همچنین به ویژگیهای زمینهای پنهان مانند تاریخچه کاربر، وضعیت جلسه، و جاسازیهایی که برای ناظران خارجی غیرشفاف هستند، بستگی دارند. آنچه پلتفرمها به عنوان «حجم سریع» میفروشند، یک تخمین مدلسازی شده است، نه اندازهگیری مستقیم.
2. پاسخ های LLM طبیعتاً غیر قطعی هستند
حجم کلمات کلیدی سنتی به این دلیل کار می کند که میلیون ها نفر همان عبارت را در گوگل تایپ می کنند و این پرسش ها ثبت می شوند. تعاملات هوش مصنوعی اساساً متفاوت است. رفتار جستجو در سئوی سنتی تکراری است، با میلیونها عبارت یکسان که معیارهای حجم پایدار را نشان میدهد. تعاملات LLM محاوره ای و متغیر است. افراد سؤالات را به گونهای متفاوت بیان میکنند، اغلب در یک جلسه واحد، که تشخیص الگو را با مجموعه دادههای کوچک سختتر میکند.
این غیر جبرگرایی در چگونگی کارکرد LLM ساخته شده است. آنها متن را با استفاده از روش های احتمالی تولید می کنند و کلمات را بر اساس احتمال آنها به جای پیروی از یک الگوی مشخص انتخاب می کنند. همین اعلان میتواند پاسخهای متفاوتی را ایجاد کند، که نتیجهگیری منسجم و دقیق را دشوار میکند.
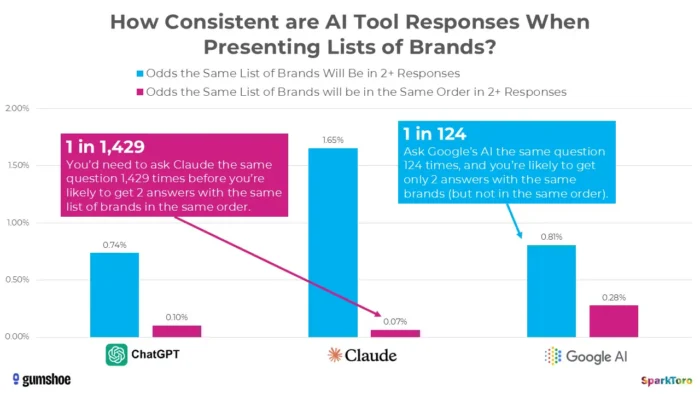
3. تحقیقات SparkToro نشان میدهد که رتبهبندیها اساساً تصادفی هستند
قانعکنندهترین شواهد از مطالعه تاریخی ژانویه 2026 توسط رند فیشکین و Gumshoe.ai به دست آمده است. آنها 2961 درخواست را روی 600 داوطلب در ChatGPT، Claude و Google AI آزمایش کردند. یافته: در هر دو پاسخ، کمتر از یک در 100 شانس دریافت لیست برند یکسان وجود دارد و کمتر از یک در 1000 شانس همان لیست به ترتیب مشابه وجود دارد. همانطور که فیشکین به صراحت نتیجه گرفت، هر ابزاری که «موقعیت رتبهبندی در هوش مصنوعی» را ایجاد کند، اساساً آن را ایجاد میکند.
منبع
تحقیقات SparkToro تنوع قابلتوجهی را در توصیههای برند تولید شده توسط هوش مصنوعی نشان میدهد، حتی زمانی که از اعلانهای یکسان استفاده میشود، و نشان میدهد که اندازهگیریهای دید هوش مصنوعی نقطهبهوقت ممکن است نوسانات را به جای سیگنالهای عملکرد بادوام منعکس کند.
4. روش شناسی مبتنی بر پانل دارای مشکلات سوگیری ذاتی است
پلتفرمهایی مانند پروفوند برای منبع دادههای سریع خود به پنلهای مصرفکننده انتخابی متکی هستند. عمیق به مکالمات از پنلهای مصرفکننده چندگانه و دوبله از کاربران موتور پاسخگوی واقعی، با مقیاس صدها میلیون درخواست در ماه مجوز میدهد و از مدلسازی احتمالی پیشرفته برای برونیابی فرکانس، هدف و احساسات در سطح وسیعتر استفاده میکند.جمعیت ها
منبع
در حالی که این امر قوی به نظر می رسد، ماهیت انتخاب این پانل ها به این معنی است که نمونه ممکن است به سمت کاربران متعهدتر و متعهدتر در زمینه فناوری منحرف شود، نه نماینده ای از نحوه درخواست مردم از ابزارهای هوش مصنوعی.
5. پرس و جوهای API رفتار واقعی انسان را منعکس نمی کنند
بسیاری از ابزارها مدلهای هوش مصنوعی را از طریق API جستجو میکنند تا درخواستهای کاربر را شبیهسازی کنند، اما این شکاف دیگری را ایجاد میکند. بیشتر ابزارهای ردیابی هوش مصنوعی به جای تقلید از استفاده از رابط انسانی به فراخوانی های API متکی هستند، و تحقیقات اولیه نشان می دهد که نتایج API ممکن است با نتایج رابط متفاوت باشد، اگرچه بزرگی و پیامدهای این تفاوت ها نیاز به بررسی بیشتر دارد. ماهیت مبتنی بر API دادههای پرسوجو همچنین به این معنی است که نتایج با آنچه انسانها واقعاً جستجو میکنند همسو نیستند.
6. رانش نقل قول عظیم و غیرقابل پیش بینی است
حتی اگر همه موارد فوق را نادیده بگیرید، پایداری ماه به ماه استنادهای هوش مصنوعی به طرز تکان دهنده ای پایین است. مطالعهای که توسط Profound انجام شد، تغییر استناد را در هر ماه اندازهگیری کرد و تغییرات بسیار زیادی را در دامنههای ذکر شده حتی برای درخواستهای یکسان مشاهده کرد. Google AI Overviews و ChatGPT تغییرات ماهانه ده ها درصد را نشان دادند.
منبع
این بدان معناست که "حجم" متصل به هر درخواست معین امروز ممکن است ماه آینده کاملاً متفاوت به نظر برسد و آن را به پایه ای غیرقابل اعتماد برای تصمیمات سرمایه گذاری محتوا تبدیل کند.
7. ما در دوره پیش از سمرش هستیم: ابزارها هنوز زیرساخت ندارند
ما هنوز در دوره پیش از Semrush/Moz/Ahrefs برای LLM هستیم. امروزه هیچ کس به تأثیر LLM روی کسب و کار خود دید کاملی ندارد. مراقب هر فروشنده یا مشاوری باشید که وعده دید کامل را می دهد، زیرا این امر هنوز امکان پذیر نیست. دادههای ردیابی کنونی باید بهعنوان جهتدار و مفید برای تصمیمگیری در نظر گرفته شوند، اما نه قطعی.
بهترین روشهای بهینهسازی موتور مولد: در عوض چه باید کرد؟
صدای سریع یکی از سیگنالهای بسیاری است و در حال حاضر یکی از ضعیفترهاست. در اینجا بهترین روشهای بهینهسازی موتور مولد هستند که واقعاً پابرجا هستند.
با ICP خود شروع کنید، نه با داشبورد
به جای اینکه اجازه دهید حجم تخمین زده شده اولویت های محتوای GEO شما را تعیین کند، با آنچه واقعاً در مورد مخاطبان خود می دانید شروع کنید. قوی ترین سیگنالی که دارید، نمایه مشتری ایده آل شما است. بهترین مشتریان شما برای حل چه مشکلاتی شما را استخدام می کنند؟ آنها از چه زبانی برای توصیف آن مشکلات استفاده می کنند؟ این نقاط درد، نه تخمینهای سریع مدلسازی شده فروشنده، باید پایه و اساس آنچه در پاسخهای هوش مصنوعی بهینهسازی میکنید باشد.
منبع: The Smarketers
اگر کار ICP محکمی انجام دادهاید، در حال حاضر روی دادههای بهتری از هر ابزار حجم سریعی که میتواند به شما بدهد، نشستهاید.
به جایی بروید که مخاطبان شما از قبل صحبت می کنند
با رفتن به جایی که مخاطبان شما آشکارا و صادقانه صحبت می کنند، در تحقیقات مخاطب واقعی لایه لایه شوید. موضوعات Reddit، انجمنهای تخصصی، نظرات لینکدین، انجمنهای Slack و سایتهای بررسی مانند G2 و Trustpilot مکانهایی هستند که افراد به زبان خودشان سوالات بدون فیلتر میپرسند. این دقیقاً همان نوع زبان طبیعی است که دقیقاً به نحوه درخواست ابزار هوش مصنوعی توسط شخصی نشان می دهد. اگر ICP شما به طور مکرر از شما میپرسد که «چگونه میتوانم بازگشت سرمایه X را برای مدیر مالی خود توجیه کنم» در یک Subreddit، این خلاصه محتوایی بسیار مطمئنتر از یک شماره حجم فوری است که به یک درخواست تهیهشده توسط فروشنده پیوست شده است.
گفتگوهای مشتری خود را استخراج کنید
تیم های رویارویی با مشتری یکی از کم استفاده ترین منابع هوش GEO هستند. ضبط تماسهای فروش، بلیطهای پشتیبانی، مصاحبههای مشتری و مکالمههای حضوری سرشار از عبارات دقیقی هستند که خریداران واقعی هنگام گیر کردن، شک و تردید یا ارزیابی گزینهها استفاده میکنند. آن زبان در محتوای شما و در نهایت در پاسخ های هوش مصنوعی تعلق دارد. اگر تیم فروش شما هر هفته همین اعتراض را می شنود، به احتمال زیاد کسی همان سوال را از هوش مصنوعی می پرسد.
اعلان ها را در اطراف زبان مخاطب خود دسته بندی و سازماندهی کنید
هنگامی که ورودی خام از کار ICP، انجمن ها و مکالمات مشتری خود را دریافت کردید، گام بعدی ساختار آن است. به جای اینکه هر درخواست بالقوه را به عنوان یک هدف مجزا در نظر بگیرید، آنها را بر اساس هدف و موضوع گروه بندی کنید.
خوشهبندی سریع پیرامون موضوعات مشابه یا نقاط دردناک به شما کمک میکند الگوهایی را در نحوه تفکر مخاطبانتان در مورد یک مشکل ببینید، نه فقط نحوه بیان یک سؤال را. مجموعهای پیرامون «چگونگی اندازهگیری موفقیت GEO» ممکن است شامل اعلانهایی در مورد معیارها، گزارشدهی، ارتباطات ذینفعان و معیار باشد. هر یک از آن ها مستحق محتوا هستند، و همپوشانی بین آنها به شما می گوید که روایت اصلی شما باید چه باشد.
این یک تغییر معنادار ازمنطق تحقیق کلمه کلیدی هنگامی که به GEO در مقابل AEO فکر می کنید، اصل سازماندهی یکسان می ماند: قدرت موضوعی در مورد مشکلاتی که مخاطب شما سعی در حل آنها دارد. سازماندهی سریع بر اساس هدف و مضمون چیزی است که به شما امکان می دهد آن اختیار را به طور سیستماتیک ایجاد کنید.
از ابزارهای Prompt Volume برای آنچه که در واقع خوب هستند استفاده کنید
هیچ کدام از اینها به معنای کنار گذاشتن کامل پلتفرم هایی مانند Profound یا Writesonic نیست. اگر به درستی استفاده شوند، واقعاً برای آگاهی جهتگیری مفید هستند: شناسایی شکافهای موضوعی، نظارت بر اینکه آیا نام تجاری شما در مکالمات درست ظاهر میشود یا خیر، و ردیابی سهم صدا در مقابل رقبا در طول زمان.
منبع
اشتباه این است که از آنها به عنوان جایگزینی برای حجم کلمه کلیدی استفاده می کنیم و اجازه می دهیم برآوردهای آنها آنچه را که ایجاد می کنید هدایت کند. اجازه دهید ICP، تحقیقات مخاطبان، و گفتگوهای واقعی مشتری به شما بگوید برای چه چیزی بهینه سازی کنید. سپس از داده های حجم سریع برای تست فشار و نظارت استفاده کنید، نه برای تصمیم گیری.
یک برنامه نظارتی بسازید که در واقع کار کند
با توجه به میزان جابهجایی استناد در خروجیهای هوش مصنوعی، نظارت به جای واکنشی، باید ساختارمند و سازگار باشد. بررسی نمایان بودن هوش مصنوعی برندتان هر سه ماه یکبار کافی نیست. یک برنامه نظارت ماهانه برای خوشههای فوری اصلی شما یک خط پایه منطقی برای تشخیص تغییرات معنیدار بدون شاخصسازی بیش از حد نویز به شما میدهد.
در اینجا نحوه برخورد عملی به آن آمده است. یک لیست تعریف شده از 20 تا 30 درخواست تنظیم کنید که منعکس کننده رایج ترین سوالات ICP شما باشد. آنها را حداقل به صورت ماهانه روی پلتفرمهایی که مخاطبان شما بیشتر استفاده میکنند، مانند ChatGPT، Perplexity، و Google AI Overviews، روی یک آهنگ تنظیم شده اجرا کنید. ردیابی کنید که آیا نام تجاری، محتوای شما یا رقبای شما ظاهر می شوند یا خیر. به تغییرات توجه داشته باشید، اما با توجه به تنوع زیاد، نسبت به نوسانات یک ماهه بیش از حد واکنش نشان ندهید. آنچه شما به دنبال آن هستید، روندهای جهت دار طی سه تا شش ماه است، نه موقعیت های هفته به هفته.
این چیزی است که تیمهایی را که دارای استراتژی بهینهسازی جستجوی هوش مصنوعی واقعی هستند از آنهایی که به هشدارهای داشبورد واکنش نشان میدهند، جدا میکند. نظارت به اطلاع می رساند؛ تصمیم نمی گیرد
خط پایین
Prompt volume تلاش می کند تا تقاضایی را که ممکن است قبلاً مستقیماً به آن دسترسی داشته باشید، تقریبی کند. برندهایی که در جستجوی هوش مصنوعی برنده می شوند، آنهایی نیستند که به دنبال درخواست هایی نیستند که بیشترین ردیابی را دارند. آنها کسانی هستند که مخاطبان خود را به اندازه کافی عمیقا درک می کنند تا در پاسخ هایی که مشتریان واقعاً به دنبال آن هستند نشان داده شوند.
