Večina nasvetov o najboljših praksah generativne optimizacije mehanizmov se začne na istem mestu: poiščite pozive, ki jih ljudje uporabljajo z orodji AI, spremljajte, katera zagotavljajo prepoznavnost vaše blagovne znamke, in gradite vsebino okoli poizvedb z največjim obsegom.
Težava? Ti podatki so v veliki meri ocenjeni.
Generativna optimizacija motorja (GEO) je še vedno dovolj nova, da infrastruktura za njeno natančno merjenje še ne obstaja. Pomislite, kako se GEO razlikuje od SEO: zreli, zanesljivi signali, ki ste jih pričakovali od orodij, kot sta Semrush ali Ahrefs, so se razvijala leta. GEO meritev še ni. To, čemur platforme pravijo »prompt volume«, je modelirano, ocenjeno in pogosto napačno usmerjeno.
Ta objava pojasnjuje, zakaj je takojšnji obseg nezanesljiv temelj za vašo GEO strategijo in kaj namesto tega počnejo najuspešnejše ekipe.
Ključni zaključki
»Takojšnji obseg« je modelirana ocena in ne dejanski uporabniški podatek, zaradi česar je nezanesljivo izhodišče za odločitve GEO.
Obnašanje AI je nedosledno; ljudje fraze pozivajo drugače in modeli vračajo različne odgovore, zaradi česar je vzorcem v majhnem obsegu težko zaupati.
»Uvrstitve« AI so nestabilne; študije kažejo, da se rezultati nenehno spreminjajo, zato sledenje položaju na način, na katerega sledite SEO, ne pomeni.
Večina podatkovnih virov, ne glede na to, ali so plošče ali API-ji, je pristranskih ali ne odražajo dejanskega vedenja uporabnikov v orodjih AI.
Premik navedb je velik, kar pomeni, da se viri in vidnost spreminjajo iz meseca v mesec tudi za enake pozive.
Orodja GEO so še zgodnja in usmerjena, niso dokončna; ravnajte z njimi ustrezno.
Pozivi za združevanje v gruče okoli dejanskega jezika vašega ICP prekašajo lovljenje seznamov poizvedb, ki jih pripravi prodajalec.
Dosleden urnik spremljanja je pomembnejši od obsedenosti s katero koli posamezno podatkovno točko.
Zakaj hitri obseg zavaja vašo GEO strategijo
1. LLM nimajo obsega iskanja: je ocenjen, ne izmerjen
Najbolj temeljna težava je, da ni pravega "obsega iskanja z umetno inteligenco", na katerega Google razkriva podatke o iskalni poizvedbi. Študentje LLM ne objavljajo ustreznikov pogostosti poizvedb ali obsega iskanja. Njihovi odgovori se razlikujejo, včasih subtilno in včasih dramatično, tudi za enake poizvedbe, zaradi verjetnostnega dekodiranja in hitrega konteksta. Odvisni so tudi od skritih kontekstualnih funkcij, kot so uporabniška zgodovina, stanje seje in vdelave, ki niso pregledne za zunanje opazovalce. To, kar platforme prodajajo kot "takojšen obseg", je modelirana ocena in ne neposredna meritev.
2. Odzivi LLM so po naravi nedeterministični
Tradicionalni obseg ključnih besed deluje, ker milijoni ljudi vnesejo isto frazo v Google in te poizvedbe se zabeležijo. Interakcije AI so bistveno drugačne. Obnašanje iskanja v tradicionalnem SEO se ponavlja, z milijoni enakih besednih zvez, ki poganjajo stabilne meritve obsega. LLM interakcije so pogovorne in spremenljive. Ljudje različno preoblikujejo vprašanja, pogosto v eni seji, zaradi česar je prepoznavanje vzorcev težje z majhnimi nabori podatkov.
Ta nedeterminizem je vpet v delovanje LLM. Besedilo ustvarjajo z uporabo verjetnostnih metod, pri čemer izbirajo besede na podlagi njihove verjetnosti, namesto da sledijo določenemu vzorcu. Enak poziv lahko povzroči različne odzive, zaradi česar je težko narediti dosledne in natančne zaključke.
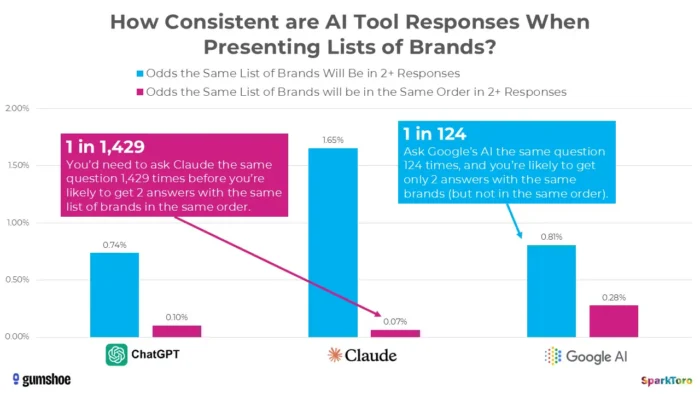
3. Raziskava podjetja SparkToro kaže, da so uvrstitve v bistvu naključne
Najbolj prepričljivi dokazi prihajajo iz prelomne študije iz januarja 2026, ki sta jo izvedla Rand Fishkin in Gumshoe.ai. Preizkusili so 2.961 pozivov pri 600 prostovoljcih na ChatGPT, Claude in Google AI. Ugotovitev: obstaja manj kot ena proti 100 možnosti, da dobite isti seznam blagovnih znamk v katerih koli dveh odgovorih, in manj kot ena proti 1000 možnosti za isti seznam v istem vrstnem redu. Kot je odkrito zaključil Fishkin, je vsako orodje, ki daje "položaj na lestvici v AI", v bistvu izmišljevanje.
Vir
Raziskave podjetja SparkToro poudarjajo znatno variabilnost v priporočilih blagovne znamke, ki jih ustvari umetna inteligenca, tudi če so uporabljeni enaki pozivi, kar nakazuje, da lahko meritve vidnosti umetne inteligence v trenutku odražajo nestanovitnost in ne trajne signale delovanja.
4. Metodologija, ki temelji na panelih, ima prirojene težave s pristranskostjo
Platforme, kot je Profound, se zanašajo na opt-in potrošniške plošče za pridobivanje svojih hitrih podatkov. Profound licencira pogovore iz več, dvojno opt-in potrošniških panelov dejanskih uporabnikov mehanizmov za odzivnike, z obsegom v stotinah milijonov pozivov na mesec, in uporablja napredno verjetnostno modeliranje za ekstrapolacijo frekvence, namere in občutkov v širšempopulacije.
Vir
Čeprav se to sliši robustno, narava izbire teh panelov pomeni, da se lahko vzorec nagiba k bolj tehnično podkovanim in angažiranim uporabnikom, ne pa k reprezentativnemu prerezu tega, kako splošna populacija dejansko spodbuja orodja AI.
5. Poizvedbe API ne odražajo resničnega človeškega vedenja
Mnoga orodja poizvedujejo po modelih umetne inteligence prek API-ja za simulacijo uporabniških pozivov, vendar to uvaja še eno vrzel. Večina orodij za sledenje z umetno inteligenco se zanaša na klice API-ja, namesto da posnema uporabo človeškega vmesnika, zgodnje raziskave pa kažejo, da se lahko rezultati API-ja razlikujejo od rezultatov vmesnika, čeprav obseg in posledice teh razlik zahtevajo nadaljnjo preiskavo. Narava poizvedovanja po podatkih, osredotočena na API, pomeni tudi, da rezultati niso usklajeni s tem, kar ljudje dejansko iščejo.
6. Zamik citatov je ogromen in nepredvidljiv
Tudi če zanemarite vse zgoraj, je mesečna stabilnost navedb AI šokantno nizka. Študija, ki jo je izvedel Profound, je merila nihanje citiranosti iz meseca v mesec in opazila zelo velike spremembe v citiranih domenah tudi pri enakih pozivih. Google AI Overviews in ChatGPT sta pokazala mesečne razlike v desetinah odstotnih točk.
Vir
To pomeni, da bo »glasnost«, ki je danes priložena kateremu koli pozivu, lahko naslednji mesec videti popolnoma drugačna, zaradi česar je nezanesljiva podlaga za odločitve o naložbah v vsebino.
7. Smo v obdobju pred Semrushom: orodja še nimajo infrastrukture
Še vedno smo v obdobju pred Semrush/Moz/Ahrefs za LLM. Danes nihče nima popolnega vpogleda v vpliv LLM na svoje poslovanje. Bodite previdni pri prodajalcih ali svetovalcih, ki obljubljajo popolno prepoznavnost, ker to preprosto še ni mogoče. Trenutne podatke o sledenju je treba obravnavati kot usmerjevalne in uporabne za odločitve, ne pa kot dokončne.
Najboljše prakse za optimizacijo generativnega motorja: Kaj storiti namesto tega
Hitra glasnost je eden izmed mnogih signalov in trenutno je eden šibkejših. Tukaj so najboljše prakse generativne optimizacije motorja, ki dejansko vzdržijo.
Začnite s svojim ICP, ne z nadzorno ploščo
Namesto da dovolite, da ocenjeni takojšnji obseg narekuje vaše prednostne naloge glede vsebine GEO, začnite s tem, kar dejansko veste o svojem občinstvu. Najmočnejši signal, ki ga imate, je vaš profil idealne stranke. Za reševanje katerih težav vas najemajo vaše najboljše stranke? Kateri jezik uporabljajo za opis teh težav? Te boleče točke, ne prodajalčeve modelirane takojšnje ocene, bi morale biti osnova za to, za kaj optimizirate odgovore AI.
Vir: The Smarketers
Če ste dobro opravili ICP, že imate boljše podatke, kot vam jih lahko zagotovi katero koli orodje za hitro glasnost.
Pojdite tja, kjer vaše občinstvo že govori
Vstopite v pravo raziskavo občinstva, tako da greste tja, kjer vaše občinstvo govori odkrito in pošteno. Teme Reddit, nišni forumi, komentarji na LinkedInu, skupnosti Slack in spletna mesta z ocenami, kot sta G2 in Trustpilot, so mesta, kjer ljudje postavljajo nefiltrirana vprašanja z lastnimi besedami. To je natanko tak naravni jezik, ki se zelo ujema s tem, kako bi nekdo pozval orodje AI. Če vaš ICP večkrat sprašuje "kako naj upravičim donosnost naložbe X svojemu finančnemu direktorju" v subredditu, je to veliko bolj zanesljiva povzetek vsebine kot takojšnja številka obsega, priložena poizvedbi, ki jo je pripravil prodajalec.
Izkopavajte lastne pogovore s strankami
Ekipe, ki se soočajo s strankami, so eden najbolj premalo uporabljenih virov GEO inteligence. Posnetki prodajnih klicev, vstopnice za podporo, intervjuji s strankami in uvodni pogovori so bogati z natančnimi izrazi, ki jih resnični kupci uporabljajo, ko so obtičali, skeptični ali ocenjujejo možnosti. Ta jezik sodi v vašo vsebino in navsezadnje v odgovore AI. Če vaša prodajna ekipa vsak teden sliši isti ugovor, obstaja velika verjetnost, da nekdo AI postavlja isto vprašanje.
Združite in organizirajte pozive okoli jezika vašega občinstva
Ko imate neobdelane vhode iz svojega dela ICP, forumov in pogovorov s strankami, je naslednji korak njihovo strukturiranje. Namesto da bi vsak potencialni poziv obravnavali kot izoliran cilj, jih razvrstite v skupine po namenu in temi.
Hitro združevanje okoli podobnih tem ali bolečinskih točk vam pomaga videti vzorce v tem, kako vaše občinstvo razmišlja o problemu, ne le v tem, kako izrazi posamezno vprašanje. Grozd okoli »kako izmeriti uspeh GEO« lahko vključuje pozive o meritvah, poročanju, komunikaciji z deležniki in primerjalni analizi. Vsak od teh si zasluži vsebino in prekrivanje med njimi vam pove, kakšna bi morala biti vaša osrednja pripoved.
To je pomemben premik odlogiko raziskovanja ključnih besed. Ko razmišljate o GEO proti AEO, organizacijsko načelo ostaja enako: aktualna avtoriteta za težave, ki jih vaše občinstvo poskuša rešiti. Hitra organizacija po namenu in temi je tisto, kar vam omogoča, da to avtoriteto sistematično gradite.
Uporabite orodja Prompt Volume Tools za tisto, v čemer so dejansko dobri
Nič od tega ne pomeni popolne opustitve platform, kot sta Profound ali Writesonic. Če se pravilno uporabljajo, so resnično uporabni za usmerjanje ozaveščenosti: odkrivanje vrzeli v temah, spremljanje, ali se vaša blagovna znamka pojavlja v pravih pogovorih, in sledenje deležu glasu v primerjavi s konkurenti skozi čas.
Vir
Napaka je, da jih uporabljate kot nadomestek za obseg ključnih besed in dovolite, da njihove ocene poganjajo to, kar ustvarjate. Naj vam vaš ICP, raziskave občinstva in pogovori s pravimi strankami povedo, za kaj optimizirati. Nato uporabite takojšnje podatke o volumnu za testiranje tlaka in spremljanje, ne za odločanje.
Sestavite urnik spremljanja, ki dejansko deluje
Glede na to, koliko odstopanja citatov obstaja v rezultatih umetne inteligence, mora biti spremljanje strukturirano in dosledno, ne pa reaktivno. Preverjanje prepoznavnosti AI vaše blagovne znamke enkrat na četrtletje ni dovolj. Mesečni razpored spremljanja za vaše osrednje grozde pozivov vam daje razumno osnovo za odkrivanje pomembnih premikov brez pretiranega indeksiranja hrupa.
Evo, kako k temu pristopite praktično. Nastavite določen seznam 20 do 30 pozivov, ki odražajo najpogostejša vprašanja vašega ICP. Izvajajte jih z določeno frekvenco, vsaj enkrat mesečno, na platformah, ki jih vaše občinstvo največ uporablja, kot so ChatGPT, Perplexity in Google AI Overviews. Spremljajte, ali se pojavlja vaša blagovna znamka, vaša vsebina ali vaši konkurenti. Upoštevajte spremembe, vendar ne pretiravajte z enomesečnimi nihanji glede na to, koliko variacij obstaja. Tisto, kar opazujete, so smerni trendi v treh do šestih mesecih, ne položaji iz tedna v teden.
To je tisto, kar loči ekipe s pravo strategijo optimizacije iskanja z umetno inteligenco od tistih, ki se odzivajo na opozorila na nadzorni plošči. Spremljanje obvešča; ne odloča.
Bottom Line
Glasnost poziva poskuša približati povpraševanje, do katerega morda že imate neposreden dostop. Blagovne znamke, ki zmagajo pri iskanju z umetno inteligenco, niso tiste, ki lovijo najbolj sledene pozive. Oni so tisti, ki svoje občinstvo razumejo dovolj globoko, da se pokažejo v odgovorih, ki jih njihove stranke dejansko iščejo.
