Повечето съвети относно най-добрите практики за генеративна оптимизация на двигателя започват от едно и също място: намерете подканите, които хората използват с AI инструменти, проследете кои дават видимост на вашата марка и изградете съдържание около най-обемните заявки.
проблемът? Тези данни са до голяма степен приблизителни.
Генеративната оптимизация на двигателя (GEO) все още е достатъчно нова, така че инфраструктурата за нейното точно измерване все още не съществува. Помислете как GEO се различава от SEO: зрелите, надеждни сигнали, които очаквате от инструменти като Semrush или Ahrefs, отнеха години за разработване. Измерването на GEO все още не е там. Това, което платформите наричат „бърз обем“, е моделирано, оценено и често насочено погрешно.
Тази публикация обяснява защо бързият обем е ненадеждна основа за вашата GEO стратегия и какво правят най-добре представящите се екипи вместо това.
Ключови изводи
„Бърз обем“ е моделирана оценка, а не действителни потребителски данни, което го прави ненадеждна отправна точка за GEO решения.
Поведението на ИИ е непоследователно; хората фразират подкани по различен начин и моделите връщат различни отговори, което прави моделите трудни за доверие в малък мащаб.
„Класирането“ на AI е нестабилно; проучванията показват, че резултатите се променят постоянно, така че проследяването на позицията по начина, по който проследявате SEO, не се превежда.
Повечето източници на данни, независимо дали са панели или API, са предубедени или не отразяват реалното потребителско поведение в инструментите за изкуствен интелект.
Дрейфът на цитиранията е висок, което означава, че източниците и видимостта се променят от месец на месец дори за идентични подкани.
GEO инструментите са все още ранни и насочващи, а не окончателни; третирайте ги съответно.
Подканите за клъстериране около действителния език на вашия ICP превъзхождат преследването на подбрани от доставчика списъци със заявки.
Последователният график за наблюдение е по-важен от обсебването на която и да е точка от данни.
Защо бързият обем подвежда вашата GEO стратегия
1. LLMs нямат обем на търсене: Той е прогнозен, а не измерен
Най-фундаменталният проблем е, че няма истински „обем на търсене с изкуствен интелект“ по начина, по който Google излага данните от заявките за търсене. LLM не публикуват еквиваленти на честотата на заявките или обема на търсене. Техните отговори варират, понякога едва доловимо, а понякога драстично, дори за идентични заявки, поради вероятностно декодиране и бърз контекст. Те също зависят от скрити контекстуални функции като потребителска история, състояние на сесия и вграждания, които са непрозрачни за външни наблюдатели. Какво платформите продават като „бърз обем“ е моделирана оценка, а не директно измерване.
2. Отговорите на LLM са недетерминистични по природа
Традиционният обем на ключовите думи работи, защото милиони хора въвеждат една и съща фраза в Google и тези заявки се регистрират. Взаимодействията на AI са фундаментално различни. Поведението при търсене при традиционното SEO е повтарящо се, с милиони идентични фрази, водещи до стабилни показатели за обем. LLM взаимодействията са разговорни и променливи. Хората перифразират въпросите по различен начин, често в рамките на една сесия, което прави разпознаването на образи по-трудно с малки набори от данни.
Този недетерминизъм е заложен в начина, по който работят LLM. Те произвеждат текст, използвайки вероятностни методи, като избират думи въз основа на тяхната вероятност, вместо да следват определен модел. Една и съща подкана може да доведе до различни отговори, което затруднява правенето на последователни и точни заключения.
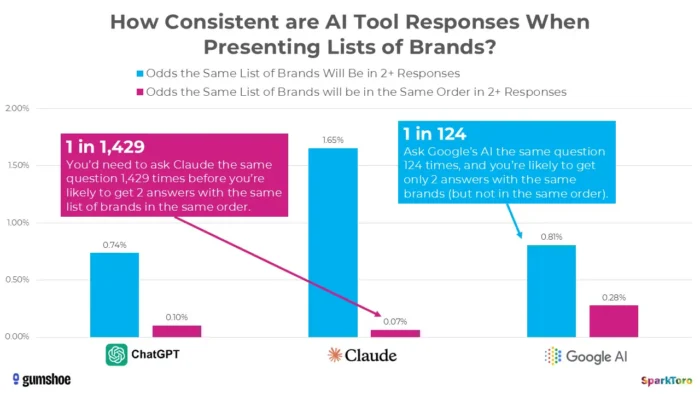
3. Изследванията на SparkToro показват, че класирането е по същество произволно
Най-убедителните доказателства идват от забележително проучване от януари 2026 г. на Ранд Фишкин и Gumshoe.ai. Те тестваха 2961 подкани сред 600 доброволци в ChatGPT, Claude и Google AI. Констатацията: има шанс по-малко от едно на 100 да получите списък с една и съща марка във всеки два отговора и шанс по-малко от едно на 1000 за същия списък в същия ред. Както Фишкин направо заключи, всеки инструмент, който дава „позиция за класиране в AI“, всъщност го измисля.
Източник
Изследване от SparkToro подчертава значителна променливост в генерираните от AI препоръки за марка, дори когато се използват идентични подкани, което предполага, че измерванията на видимостта на AI в даден момент може да отразяват променливост, а не трайни сигнали за ефективност.
4. Базираната на панел методология има присъщи проблеми с пристрастията
Платформи като Profound разчитат на потребителски панели за включване, за да извличат своите бързи данни. Profound лицензира разговори от множество потребителски панели с двойно включване на реални потребители на машина за отговори, с мащаб от стотици милиони подкани на месец и прилага усъвършенствано вероятностно моделиране за екстраполиране на честота, намерение и настроения в по-широк планпопулации.
Източник
Въпреки че това звучи стабилно, естеството на тези панели за включване означава, че извадката може да се изкриви към по-технологично разбираеми, ангажирани потребители, а не към представително напречно сечение на това как общото население действително подсказва AI инструменти.
5. API заявките не отразяват реалното човешко поведение
Много инструменти правят запитвания към AI модели чрез API, за да симулират потребителски подкани, но това въвежда друга празнина. Повечето инструменти за проследяване на AI разчитат на API извиквания, вместо да имитират използването на човешки интерфейс, и ранните изследвания показват, че резултатите от API може да се различават от резултатите от интерфейса, въпреки че мащабът и последиците от тези разлики изискват допълнително проучване. Фокусираният върху API характер на заявките за данни също означава, че резултатите не са съобразени с това, което хората действително търсят.
6. Дрейфът на цитирания е огромен и непредвидим
Дори и да игнорирате всичко по-горе, месечната стабилност на цитиранията на AI е шокиращо ниска. Проучване на Profound измерва отклонението на цитиранията месец след месец и наблюдава много големи промени в цитираните домейни дори при идентични подкани. Google AI Overviews и ChatGPT показаха месечни вариации от десетки процентни пункта.
Източник
Това означава, че „обемът“, прикрепен към дадена подкана днес, може да изглежда напълно различно следващия месец, което го прави ненадеждна основа за решения за инвестиране в съдържание.
7. Ние сме в ера преди Semrush: Инструментите все още нямат инфраструктурата
Все още сме в ера преди Semrush/Moz/Ahrefs за LLM. Никой няма пълна видимост за въздействието на LLM върху бизнеса им днес. Бъдете внимателни към всеки продавач или консултант, който обещава пълна видимост, защото това просто все още не е възможно. Текущите данни за проследяване трябва да се третират като насочващи и полезни за решения, но не като окончателни.
Най-добри практики за генерираща оптимизация на двигателя: Какво да направите вместо това
Бързата сила на звука е един от многото сигнали и в момента е един от по-слабите. Ето най-добрите практики за генеративна оптимизация на двигателя, които всъщност издържат.
Започнете с вашия ICP, а не с табло за управление
Вместо да позволявате на прогнозния обем на бързата информация да диктува вашите приоритети за GEO съдържание, започнете с това, което всъщност знаете за вашата аудитория. Най-силният сигнал, който имате, е вашият идеален клиентски профил. За решаването на какви проблеми ви наемат най-добрите ви клиенти? Какъв език използват, за да опишат тези проблеми? Тези болезнени точки, а не моделираните бързи оценки на доставчика, трябва да бъдат в основата на това, за което оптимизирате отговорите на AI.
Източник: The Smarketers
Ако сте свършили солидна ICP работа, вече разполагате с по-добри данни, отколкото който и да е инструмент за бърз обем може да ви даде.
Отидете там, където публиката ви вече говори
Направете слой в проучването на истинската аудитория, като отидете там, където вашата публика говори открито и честно. Теми в Reddit, нишови форуми, коментари в LinkedIn, общности на Slack и сайтове за рецензии като G2 и Trustpilot са места, където хората задават нефилтрирани въпроси със собствените си думи. Това е точно видът естествен език, който се съпоставя точно с начина, по който някой би подсказал AI инструмент. Ако вашият ICP многократно пита „как да обоснова възвръщаемостта на инвестициите на X пред моя финансов директор“ в subreddit, това е далеч по-надеждно кратко съдържание, отколкото бърз номер на обем, прикрепен към курирана от доставчика заявка.
Копайте вашите собствени разговори с клиенти
Екипите, насочени към клиентите, са един от най-слабо използваните източници на GEO разузнаване. Записите на разговори за продажби, билети за поддръжка, интервюта с клиенти и разговори за въвеждане са богати с точните фрази, които истинските купувачи използват, когато са блокирани, скептични или оценяват опции. Този език принадлежи на вашето съдържание и в крайна сметка на отговорите на AI. Ако вашият екип по продажбите чува едно и също възражение всяка седмица, има голям шанс някой да зададе същия въпрос на AI.
Групирайте и организирайте подкани около езика на вашата аудитория
След като получите необработен вход от вашата ICP работа, форуми и разговори с клиенти, следващата стъпка е структурирането му. Вместо да третирате всяка потенциална подкана като изолирана цел, групирайте ги по намерение и тема.
Бързото групиране около подобни теми или болезнени точки ви помага да видите модели в това как вашата аудитория мисли за даден проблем, а не само как формулира един въпрос. Клъстер около „как да се измери успехът на GEO“ може да включва подкани относно показатели, отчитане, комуникация със заинтересованите страни и сравнителен анализ. Всеки от тях заслужава съдържание и припокриването между тях ви казва какъв трябва да бъде основният ви разказ.
Това е смислена промяна отлогика за изследване на ключови думи. Когато мислите за GEO срещу AEO, принципът на организиране остава същият: актуален авторитет около проблемите, които вашата аудитория се опитва да реши. Бързата организация по намерение и тема е това, което ви позволява систематично да изграждате този авторитет.
Използвайте инструментите за бърз обем за това, в което всъщност са добри
Нищо от това не означава пълно изоставяне на платформи като Profound или Writesonic. Използвани правилно, те са наистина полезни за насочена информираност: забелязване на пропуски в темите, наблюдение дали вашата марка се появява в правилните разговори и проследяване на дела на гласа спрямо конкурентите във времето.
Източник
Грешката е, че ги използвате като заместител на обема на ключовите думи и оставяте техните оценки да управляват това, което създавате. Нека вашето ICP, проучване на аудитория и разговори с реални клиенти ви кажат за какво да оптимизирате. След това използвайте бързи данни за обема, за да тествате налягането и да наблюдавате, а не да решавате.
Създайте график за наблюдение, който действително работи
Като се има предвид колко голямо отклонение в цитирането съществува в резултатите от ИИ, мониторингът трябва да бъде структуриран и последователен, а не реактивен. Проверяването на видимостта на AI на вашата марка веднъж на тримесечие не е достатъчно. Месечният график за наблюдение за вашите основни клъстери за подкани ви дава разумна базова линия за забелязване на значими промени без прекомерно индексиране на шума.
Ето как да подходите практически. Настройте дефиниран списък от 20 до 30 подкани, които отразяват най-честите въпроси на вашия ICP. Пускайте ги с определена честота, поне веднъж месечно, в платформите, които аудиторията ви използва най-много, като ChatGPT, Perplexity и Google AI Overviews. Проследявайте дали вашата марка, вашето съдържание или вашите конкуренти се появяват. Обърнете внимание на промените, но не реагирайте прекалено на едномесечните колебания, като се има предвид колко много вариации съществуват. Това, което наблюдавате, са насочени тенденции за три до шест месеца, а не позиции от седмица на седмица.
Това е, което разделя екипите с истинска AI стратегия за оптимизиране на търсенето от тези, които реагират на предупреждения на таблото. Мониторингът информира; не решава.
Долната линия
Подканящият обем се опитва да се приближи до търсенето, до което може би вече имате директен достъп. Марките, които печелят в търсенето с изкуствен интелект, не са тези, които преследват най-проследените подкани. Те са тези, които разбират своята аудитория достатъчно дълбоко, за да се покажат в отговорите, които техните клиенти всъщност търсят.
