De fleste rådene om gode fremgangsmåter for generativ motoroptimalisering starter på samme sted: finn ledetekstene folk bruker med AI-verktøy, spor hvilke som gir merkevaren din synlighet, og bygg innhold rundt søkene med høyest volum.
Problemet? Disse dataene er i stor grad estimert.
Generativ motoroptimalisering (GEO) er fortsatt ny nok til at infrastrukturen for å måle den nøyaktig ikke eksisterer ennå. Tenk på hvordan GEO skiller seg fra SEO: de modne, pålitelige signalene du har kommet til å forvente fra verktøy som Semrush eller Ahrefs tok år å utvikle. GEO-måling er ikke der ennå. Det plattformer kaller "promptvolum" er modellert, estimert og ofte retningsmessig feil.
Dette innlegget bryter ned hvorfor spørrevolum er et upålitelig grunnlag for din GEO-strategi og hva de best presterende teamene gjør i stedet.
Viktige takeaways
"Promptvolum" er et modellert estimat, ikke faktiske brukerdata, noe som gjør det til et upålitelig utgangspunkt for GEO-beslutninger.
AI-adferd er inkonsekvent; folk fraser spørsmål forskjellig og modeller gir varierte svar, noe som gjør mønstre vanskelig å stole på i liten skala.
AI "rangeringer" er ustabile; studier viser at resultatene endres konstant, så sporingsposisjonen slik du sporer SEO oversetter ikke.
De fleste datakilder, enten paneler eller APIer, er partiske eller reflekterer ikke reell brukeratferd i AI-verktøy.
Sitasjonsavvik er høy, noe som betyr at kilder og synlighet skifter måned til måned selv for identiske spørsmål.
GEO-verktøy er fortsatt tidlige og retningsbestemte, ikke definitive; behandle dem deretter.
Klyngering av meldinger rundt ICPs faktiske språk overgår jakten på leverandørkuraterte spørringslister.
En konsistent overvåkingsplan betyr mer enn å besette et enkelt datapunkt.
Hvorfor spørsmålsvolum villeder GEO-strategien din
1. LLM-er har ikke søkevolum: Det er estimert, ikke målt
Det mest grunnleggende problemet er at det ikke er noe ekte "AI-søkevolum" slik Google eksponerer søkedata. LLM-er publiserer ikke spørringsfrekvens eller søkevolumekvivalenter. Svarene deres varierer, noen ganger subtilt og noen ganger dramatisk, selv for identiske forespørsler, på grunn av probabilistisk dekoding og umiddelbar kontekst. De er også avhengige av skjulte kontekstuelle funksjoner som brukerhistorie, økttilstand og innebygginger som er ugjennomsiktige for eksterne observatører. Hva plattformer selger som "promptvolum" er et modellert estimat, ikke en direkte måling.
2. LLM-svar er ikke-deterministiske av natur
Tradisjonelt søkeordvolum fungerer fordi millioner av mennesker skriver inn den samme setningen i Google og disse søkene blir logget. AI-interaksjoner er fundamentalt forskjellige. Søkeatferd i tradisjonell SEO er repeterende, med millioner av identiske setninger som driver stabile volumberegninger. LLM-interaksjoner er samtalemessige og variable. Folk omformulerer spørsmål forskjellig, ofte i løpet av en enkelt økt, noe som gjør mønstergjenkjenning vanskeligere med små datasett.
Denne ikke-determinismen er bakt inn i hvordan LLM-er fungerer. De produserer tekst ved å bruke sannsynlige metoder, og velger ord basert på sannsynligheten i stedet for å følge et fast mønster. Den samme oppfordringen kan gi forskjellige svar, noe som gjør konsistente og nøyaktige konklusjoner vanskelig å trekke.
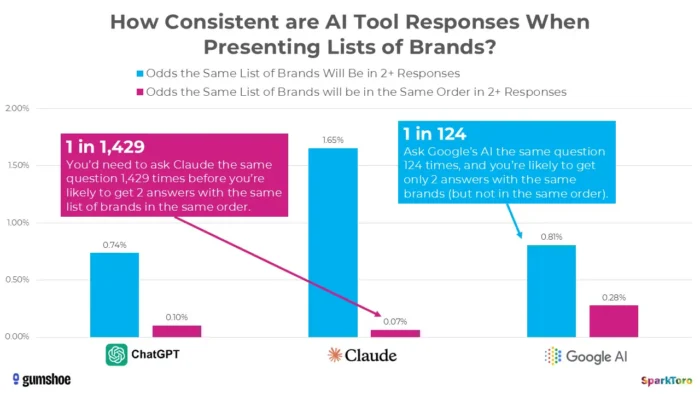
3. SparkToros forskning viser at rangeringer i hovedsak er tilfeldige
Det mest overbevisende beviset kommer fra en landemerkestudie fra januar 2026 av Rand Fishkin og Gumshoe.ai. De testet 2961 meldinger på tvers av 600 frivillige på ChatGPT, Claude og Google AI. Funnet: det er mindre enn én av 100 sjanse for å få samme merkeliste i to svar, og mindre enn én av 1000 sjanse for samme liste i samme rekkefølge. Som Fishkin rett ut konkluderte, er ethvert verktøy som gir en "rangeringsposisjon i AI" egentlig det opp.
Kilde
Forskning fra SparkToro fremhever betydelig variasjon i AI-genererte merkevareanbefalinger selv når identiske meldinger brukes, noe som tyder på at målinger av AI-synlighet på tidspunktet kan gjenspeile volatilitet i stedet for holdbare ytelsessignaler.
4. Panelbasert metodikk har iboende skjevhetsproblemer
Plattformer som Profound er avhengige av opt-in forbrukerpaneler for å hente direkte data. Profound lisensierer samtaler fra flere, dobbeltvalgte forbrukerpaneler av brukere av ekte svarmotorer, med en skala i hundrevis av millioner av meldinger per måned, og bruker avansert sannsynlighetsmodellering for å ekstrapolere frekvens, hensikt og sentiment på tvers av brederepopulasjoner.
Kilde
Selv om dette høres robust ut, betyr opt-in-naturen til disse panelene at prøven kan skjeve mot mer teknologikyndige, engasjerte brukere, ikke et representativt tverrsnitt av hvordan den generelle befolkningen faktisk ber om AI-verktøy.
5. API-spørringer reflekterer ikke ekte menneskelig atferd
Mange verktøy spør etter AI-modeller via API for å simulere brukeroppfordringer, men dette introduserer et annet gap. De fleste AI-sporingsverktøy er avhengige av API-kall i stedet for å etterligne bruk av menneskelig grensesnitt, og tidlig forskning tyder på at API-resultater kan avvike fra grensesnittresultater, selv om omfanget og implikasjonene av disse forskjellene krever ytterligere undersøkelser. Den API-fokuserte naturen til å søke etter data betyr også at resultatene ikke er på linje med det mennesker faktisk søker etter.
6. Sitasjonsdrift er massiv og uforutsigbar
Selv om du ignorerer alt ovenfor, er stabiliteten fra måned til måned for AI-siteringer sjokkerende lav. En studie av Profound målte sitasjonsdrift måned over måned og observerte svært store endringer i siterte domener selv for identiske spørsmål. Google AI Overviews og ChatGPT viste månedlige variasjoner på dusinvis av prosentpoeng.
Kilde
Dette betyr at "volumet" knyttet til en gitt forespørsel i dag kan se helt annerledes ut neste måned, noe som gjør det til et upålitelig grunnlag for beslutninger om innholdsinvesteringer.
7. Vi er i en pre-Semrush-æra: Verktøyene har ikke infrastrukturen ennå
Vi er fortsatt i en pre-Semrush/Moz/Ahrefs-æra for LLM-er. Ingen har fullstendig innsikt i LLMs innvirkning på virksomheten deres i dag. Vær forsiktig med enhver leverandør eller konsulent som lover fullstendig synlighet, for det er rett og slett ikke mulig ennå. Gjeldende sporingsdata bør behandles som retningsgivende og nyttige for beslutninger, men ikke definitive.
Gode fremgangsmåter for generativ motoroptimalisering: Hva du bør gjøre i stedet
Spørrevolum er ett av mange signaler, og akkurat nå er det et av de svakere. Her er de beste fremgangsmåtene for generativ motoroptimalisering som faktisk holder mål.
Start med ICP, ikke et dashbord
I stedet for å la estimert umiddelbar volum diktere GEO-innholdsprioriteringene dine, start med det du faktisk vet om publikummet ditt. Det sterkeste signalet du har er din ideelle kundeprofil. Hvilke problemer ansetter dine beste kunder deg for å løse? Hvilket språk bruker de for å beskrive disse problemene? Disse smertepunktene, ikke en leverandørs modellerte umiddelbare estimater, bør være grunnlaget for det du optimaliserer for i AI-svar.
Kilde: The Smarketers
Hvis du har gjort solid ICP-arbeid, sitter du allerede på bedre data enn noe prompt volumverktøy kan gi deg.
Gå dit publikum allerede snakker
Legg lag på ekte publikumsforskning ved å gå dit publikum snakker åpent og ærlig. Reddit-tråder, nisjefora, LinkedIn-kommentarer, Slack-fellesskap og anmeldelsessider som G2 og Trustpilot er steder hvor folk stiller ufiltrerte spørsmål med egne ord. Det er akkurat den typen naturlig språk som er nært tilordnet hvordan noen vil spørre et AI-verktøy. Hvis ICP-en din gjentatte ganger spør "hvordan rettferdiggjør jeg ROI av X til min CFO" i en subreddit, er det en langt mer pålitelig innholdsoversikt enn et prompt volumnummer knyttet til en leverandør-kuratert spørring.
Mine dine egne kundesamtaler
Kundevendte team er en av de mest underbrukte kildene til GEO-intelligens. Opptak av salgsanrop, supportbilletter, kundeintervjuer og introduksjonssamtaler er rike med den eksakte formuleringen som virkelige kjøpere bruker når de står fast, er skeptiske eller vurderer alternativer. Det språket hører hjemme i innholdet ditt og til slutt i AI-svarene. Hvis salgsteamet ditt hører den samme innvendingen hver uke, er det en god sjanse for at noen stiller en AI det samme spørsmålet.
Klynger og organiser forespørsler rundt publikums språk
Når du har rå input fra ICP-arbeidet ditt, fora og kundesamtaler, er neste trinn å strukturere det. I stedet for å behandle hver potensiell melding som et isolert mål, grupper dem etter hensikt og tema.
Rask gruppering rundt lignende emner eller smertepunkter hjelper deg å se mønstre i hvordan publikum tenker om et problem, ikke bare hvordan de formulerer et enkelt spørsmål. En klynge rundt "hvordan måle GEO-suksess" kan inkludere spørsmål om beregninger, rapportering, interessentkommunikasjon og benchmarking. Hver av disse fortjener innhold, og overlappingen mellom dem forteller deg hva kjernefortellingen din bør være.
Dette er et meningsfullt skifte frasøkeordforskningslogikk. Når du tenker på GEO versus AEO, forblir organiseringsprinsippet det samme: aktuell autoritet rundt problemene publikum prøver å løse. Rask organisering etter hensikt og tema er det som lar deg bygge denne autoriteten systematisk.
Bruk hurtigvolumverktøy for det de faktisk er gode på
Ingenting av dette betyr å forlate plattformer som Profound eller Writesonic helt. Brukt på riktig måte er de virkelig nyttige for retningsbevissthet: oppdage emnehull, overvåke om merkevaren din vises i de riktige samtalene, og spore stemmeandel mot konkurrenter over tid.
Kilde
Feilen er å bruke dem som en erstatning for søkeordvolum og la anslagene deres styre det du lager. La din ICP, publikumsundersøkelse og ekte kundesamtaler fortelle deg hva du skal optimalisere for. Bruk deretter prompte volumdata til å trykkteste og overvåke, ikke for å bestemme.
Lag en overvåkingsplan som faktisk fungerer
Gitt hvor mye sitasjonsdrift som eksisterer i AI-utdata, må overvåking være strukturert og konsistent i stedet for reaktiv. Det er ikke nok å sjekke merkevarens AI-synlighet en gang i kvartalet. En månedlig overvåkingsplan for kjernemeldingene dine gir deg en rimelig grunnlinje for å oppdage meningsfulle skift uten å overindeksere støy.
Her er hvordan du kan nærme deg det praktisk. Sett opp en definert liste med 20 til 30 forespørsler som gjenspeiler din ICPs vanligste spørsmål. Kjør dem på en bestemt tråkkfrekvens, minst månedlig, på tvers av plattformene publikum bruker mest, for eksempel ChatGPT, Perplexity og Google AI Overviews. Spor om merkevaren din, innholdet ditt eller konkurrentene dine vises. Legg merke til endringer, men ikke overreager på svingninger på én måned gitt hvor mye variasjon som finnes. Det du ser etter er retningstrender over tre til seks måneder, ikke stillinger fra uke til uke.
Det er dette som skiller lag med en ekte AI-søkeoptimaliseringsstrategi fra de som reagerer på dashbordvarsler. Overvåking informerer; det bestemmer ikke.
Bunnlinjen
Spørrevolum prøver å tilnærme etterspørselen som du kanskje allerede har direkte tilgang til. Merkene som vinner i AI-søk er ikke de som jager de mest sporede meldingene. Det er de som forstår publikum dypt nok til å dukke opp i svarene kundene deres faktisk ser etter.
