Die meeste advies oor die beste praktyke vir generatiewe enjinoptimalisering begin op dieselfde plek: vind die instruksies wat mense met KI-nutsgoed gebruik, spoor watter een jou handelsmerk sigbaarheid gee, en bou inhoud rondom die hoogste volume navrae.
Die probleem? Daardie data word grootliks geskat.
Generatiewe enjinoptimalisering (GEO) is nog nuut genoeg dat die infrastruktuur om dit akkuraat te meet nog nie bestaan nie. Dink aan hoe GEO van SEO verskil: die volwasse, betroubare seine wat jy van gereedskap soos Semrush of Ahrefs verwag het, het jare geneem om te ontwikkel. GEO-meting is nog nie daar nie. Wat platforms "spoedige volume" noem, is gemodelleer, beraam en dikwels rigtinggewend verkeerd.
Hierdie pos gee uiteen hoekom vinnige volume 'n onbetroubare grondslag vir jou GEO-strategie is en wat die beste presterende spanne eerder doen.
Sleutel wegneemetes
"Snelle volume" is 'n gemodelleerde skatting, nie werklike gebruikersdata nie, wat dit 'n onbetroubare beginpunt maak vir GEO-besluite.
KI-gedrag is inkonsekwent; mense fraseer aansporings anders en modelle gee uiteenlopende antwoorde, wat patrone moeilik maak om op klein skaal te vertrou.
KI-“ranglys” is onstabiel; studies toon dat resultate voortdurend verander, so die naspoorposisie van die manier waarop jy SEO opspoor, vertaal nie.
Die meeste databronne, hetsy panele of API's, is bevooroordeeld of weerspieël nie werklike gebruikersgedrag in KI-nutsgoed nie.
Aanhalingsverdryf is hoog, wat beteken dat bronne en sigbaarheid maand tot maand verskuif, selfs vir identiese opdragte.
GEO-gereedskap is nog vroeg en rigtinggewend, nie definitief nie; behandel hulle dienooreenkomstig.
Groepering van opdragte rondom jou TKP se werklike taal presteer beter as om navraelyste wat deur verskaffer saamgestel is, na te jaag.
'n Konsekwente moniteringskedule maak meer saak as obsessie oor enige enkele datapunt.
Waarom vinnige volume u GEO-strategie mislei
1. LLM's het nie soekvolume nie: dit word beraam, nie gemeet nie
Die mees fundamentele probleem is dat daar geen ware "KI-soekvolume" is soos wat Google soeknavraagdata blootstel nie. LLM's publiseer nie navraagfrekwensie of soekvolume-ekwivalente nie. Hul antwoorde verskil, soms subtiel en soms dramaties, selfs vir identiese navrae, as gevolg van waarskynlike dekodering en vinnige konteks. Hulle is ook afhanklik van verborge kontekstuele kenmerke soos gebruikergeskiedenis, sessietoestand en inbeddings wat ondeursigtig is vir eksterne waarnemers. Wat platforms verkoop as "spoedige volume" is 'n gemodelleerde skatting, nie 'n direkte meting nie.
2. LLM-antwoorde is nie-deterministies van aard
Tradisionele sleutelwoordvolume werk omdat miljoene mense dieselfde frase in Google tik en daardie navrae word aangeteken. KI-interaksies verskil fundamenteel. Soekgedrag in tradisionele SEO is herhalend, met miljoene identiese frases wat stabiele volume-metrieke bestuur. LLM-interaksies is gespreksvormend en veranderlik. Mense herformuleer vrae anders, dikwels binne 'n enkele sessie, wat patroonherkenning moeiliker maak met klein datastelle.
Hierdie nie-determinisme is gebak in hoe LLM's werk. Hulle produseer teks deur gebruik te maak van waarskynlikheidsmetodes, en kies woorde op grond van hul waarskynlikheid eerder as om 'n vasgestelde patroon te volg. Dieselfde opdrag kan verskillende antwoorde lewer, wat konsekwente en akkurate gevolgtrekkings moeilik maak om te maak.
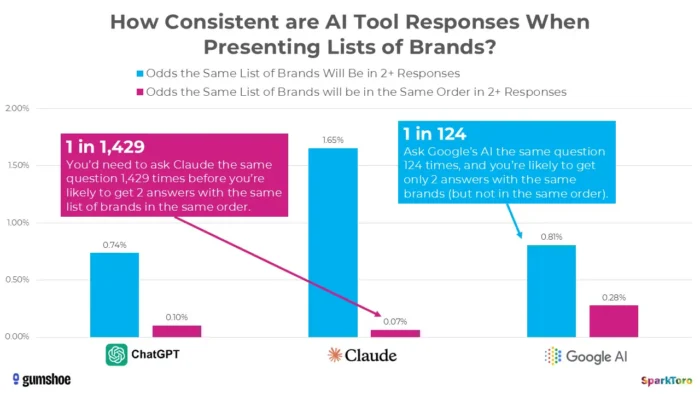
3. SparkToro se navorsing toon ranglys is in wese willekeurig
Die mees oortuigende bewyse kom uit 'n landmerk-studie van Januarie 2026 deur Rand Fishkin en Gumshoe.ai. Hulle het 2 961 aansporings oor 600 vrywilligers op ChatGPT, Claude en Google KI getoets. Die bevinding: daar is minder as 'n een uit 100 kans om dieselfde handelsmerklys in enige twee antwoorde te kry, en minder as een uit 1 000 kans op dieselfde lys in dieselfde volgorde. Soos Fishkin prontuit afgesluit het, maak enige instrument wat 'n "ranglysposisie in KI" gee dit in wese op.
Bron
Navorsing van SparkToro beklemtoon beduidende variasie in KI-gegenereerde handelsmerkaanbevelings, selfs wanneer identiese opdragte gebruik word, wat daarop dui dat punt-in-tyd KI sigbaarheidsmetings wisselvalligheid eerder as duursame prestasieseine kan weerspieël.
4. Paneelgebaseerde metodologie het inherente vooroordeelprobleme
Platforms soos Profound maak staat op intekening-verbruikerspanele om hul vinnige data te verkry. Diepgaande lisensieer gesprekke van veelvuldige verbruikerspanele van werklike antwoord-enjingebruikers, met skaal in die honderde miljoene versoeke per maand, en pas gevorderde waarskynlikheidsmodellering toe om frekwensie, bedoeling en sentiment oor breër heen te ekstrapoleerbevolkings.
Bron
Alhoewel dit robuust klink, beteken die opt-in aard van hierdie panele dat die steekproef na meer tegnologie-vaardige, betrokke gebruikers kan skeeftrek, nie 'n verteenwoordigende deursnit van hoe die algemene bevolking eintlik AI-nutsmiddels aanspoor nie.
5. API-navrae weerspieël nie werklike menslike gedrag nie
Baie nutsmiddels bevraagteken AI-modelle via API om gebruikersaanwysings te simuleer, maar dit lei tot 'n ander leemte. Die meeste KI-opsporingsinstrumente maak staat op API-oproepe eerder as om menslike koppelvlakgebruik na te boots, en vroeë navorsing dui daarop dat API-resultate van koppelvlakresultate kan verskil, hoewel die omvang en implikasies van hierdie verskille verdere ondersoek vereis. Die API-gefokusde aard van navraag na data beteken ook dat resultate nie in lyn is met dit waarna mense eintlik soek nie.
6. Aanhalingsdrift is massief en onvoorspelbaar
Selfs as jy alles hierbo ignoreer, is die maand-tot-maand-stabiliteit van KI-aanhalings skokkend laag. 'n Studie deur Profound het aanhalingsverskuiwing maand na maand gemeet en baie groot veranderinge in aangehaalde domeine waargeneem, selfs vir identiese opdragte. Google KI-oorsigte en ChatGPT het maandelikse variasies van dosyne persentasiepunte getoon.
Bron
Dit beteken dat die "volume" wat vandag aan enige gegewe opdrag geheg word, volgende maand heeltemal anders kan lyk, wat dit 'n onbetroubare grondslag maak vir inhoudbeleggingsbesluite.
7. Ons is in 'n pre-Semrush-era: die gereedskap het nog nie die infrastruktuur nie
Ons is steeds in 'n pre-Semrush/Moz/Ahrefs-era vir LLM's. Niemand het vandag volledige sigbaarheid in die impak van LLM op hul besigheid nie. Wees versigtig vir enige verkoper of konsultant wat volledige sigbaarheid belowe, want dit is eenvoudig nog nie moontlik nie. Huidige opsporingsdata moet as rigtinggewend en nuttig vir besluite hanteer word, maar nie definitief nie.
Generatiewe enjinoptimalisering Beste praktyke: Wat om eerder te doen
Vinnige volume is een sein onder baie, en op die oomblik is dit een van die swakkeres. Hier is die beste praktyke vir generatiewe enjinoptimalisering wat eintlik standhou.
Begin met jou TKP, nie 'n dashboard nie
Eerder as om die beraamde vinnige volume jou GEO-inhoudprioriteite te laat dikteer, begin met wat jy eintlik van jou gehoor weet. Die sterkste sein wat jy het, is jou ideale klantprofiel. Watter probleme huur jou beste kliënte jou om op te los? Watter taal gebruik hulle om daardie probleme te beskryf? Daardie pynpunte, nie 'n verkoper se gemodelleerde vinnige skattings nie, moet die grondslag wees van waarvoor u in KI-antwoorde optimaliseer.
Bron: The Smarketers
As jy goeie ICP-werk gedoen het, sit jy reeds op beter data as wat enige vinnige volume-instrument jou kan gee.
Gaan waar jou gehoor reeds praat
Onderrig werklike gehoornavorsing deur te gaan waar jou gehoor openlik en eerlik praat. Reddit-drade, nisforums, LinkedIn-opmerkings, Slack-gemeenskappe en resensiewebwerwe soos G2 en Trustpilot is plekke waar mense ongefilterde vrae in hul eie woorde vra. Dit is presies die soort natuurlike taal wat nou ooreenstem met hoe iemand 'n KI-instrument sou aanspoor. As jou TKP herhaaldelik vra "hoe regverdig ek die ROI van X aan my finansiële hoof" in 'n subreddit, is dit 'n baie meer betroubare inhoudsopdrag as 'n vinnige volumenommer wat aan 'n verskaffer-saamgestelde navraag gekoppel is.
Myn jou eie kliëntgesprekke
Klantgerigte spanne is een van die mees onderbenutte bronne van GEO-intelligensie. Opnames van verkoopsoproepe, ondersteuningskaartjies, klante-onderhoude en aanboordgesprekke is ryk aan die presiese frase wat regte kopers gebruik wanneer hulle vasstaan, skepties is of opsies evalueer. Daardie taal hoort in jou inhoud en uiteindelik in KI-antwoorde. As jou verkoopspan elke week dieselfde beswaar hoor, is daar 'n goeie kans dat iemand 'n KI dieselfde vraag vra.
Groepeer en organiseer boodskappe rondom jou gehoor se taal
Sodra jy rou insette van jou TKP-werk, forums en kliëntgesprekke het, is die volgende stap om dit te struktureer. Eerder as om elke potensiële aansporing as 'n geïsoleerde teiken te behandel, groepeer hulle volgens bedoeling en tema.
Vinnige groepering rondom soortgelyke onderwerpe of pynpunte help jou om patrone te sien in hoe jou gehoor oor 'n probleem dink, nie net hoe hulle 'n enkele vraag formuleer nie. 'n Groepering rondom "hoe om GEO-sukses te meet" kan aansporings oor maatstawwe, verslagdoening, kommunikasie met belanghebbendes en maatstawwe insluit. Elkeen hiervan verdien inhoud, en die oorvleueling tussen hulle vertel jou wat jou kernvertelling behoort te wees.
Dit is 'n betekenisvolle verskuiwing vanafsleutelwoordnavorsingslogika. As jy aan GEO teenoor AEO dink, bly die organiseringsbeginsel dieselfde: aktuele gesag rondom die probleme wat jou gehoor probeer oplos. Vinnige organisasie volgens bedoeling en tema is wat jou toelaat om daardie gesag sistematies te bou.
Gebruik vinnige volume gereedskap vir waarmee hulle eintlik goed is
Niks hiervan beteken om platforms soos Profound of Writesonic heeltemal te laat vaar nie. As hulle korrek gebruik word, is hulle werklik nuttig vir rigtingbewustheid: om onderwerpgapings raak te sien, te monitor of jou handelsmerk in die regte gesprekke verskyn, en om aandeel van stem teenoor mededingers oor tyd na te spoor.
Bron
Die fout is om hulle as 'n sleutelwoordvolume plaasvervanger te gebruik en hul skattings te laat dryf wat jy skep. Laat jou TKP, gehoornavorsing en werklike klantgesprekke jou vertel waarvoor om te optimaliseer. Gebruik dan vinnige volume data om druk te toets en te monitor, nie om te besluit nie.
Bou 'n moniteringskedule wat werklik werk
Gegewe hoeveel aanhalingsverskuiwing in KI-uitsette bestaan, moet monitering gestruktureer en konsekwent wees eerder as reaktief. Dit is nie genoeg om jou handelsmerk se KI-sigbaarheid een keer per kwartaal na te gaan nie. 'n Maandelikse moniteringskedule vir jou kern-spoedgroepe gee jou 'n redelike basislyn om betekenisvolle verskuiwings raak te sien sonder om geraas te oor-indekseer.
Hier is hoe om dit prakties te benader. Stel 'n gedefinieerde lys van 20 tot 30 instruksies op wat jou TKP se mees algemene vrae weerspieël. Begin dit op 'n vasgestelde kadens, ten minste maandeliks, oor die platforms wat jou gehoor die meeste gebruik, soos ChatGPT, Perplexity en Google AI Oorsigte. Volg of jou handelsmerk, jou inhoud of jou mededingers verskyn. Let op veranderinge, maar moenie oorreageer op swaaie van een maand nie, gegewe hoeveel variasie daar is. Waarna jy kyk, is rigtingstendense oor drie tot ses maande, nie week-tot-week posisies nie.
Dit is wat spanne met 'n regte KI-soekoptimaliseringstrategie skei van diegene wat op dashboard-waarskuwings reageer. Monitering lig in; dit besluit nie.
Die Bottom Line
Vinnige volume probeer om aanvraag te benader waartoe jy dalk reeds direkte toegang het. Die handelsmerke wat wen in KI-soektog, is nie dié wat die opdragte najaag nie. Dit is hulle wat hul gehoor diep genoeg verstaan om te verskyn in die antwoorde waarna hul kliënte eintlik soek.
